黑马程序员技术交流社区
标题:
集合
[打印本页]
作者:
尹善波
时间:
2012-8-1 12:54
标题:
集合
set的两种方法:HashSet、TreeSet都是无序,又不可重复,他们两个的主要区别是什么?
又是怎么实现各自的功能的(重点讲一下hashCode的特点和二叉树的运作方法)
作者:
孙建飞
时间:
2012-8-1 13:23
HashSet与TreeSet区别:
1、TreeSet 是二差树实现的,Treeset中的数据是自动排好序的,不允许放入null值
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束
3、HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的 String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例
hashcode是一种编码方式,在Java中,每个对象都会有一个hashcode,Java可以通过这个hashcode来识别一个对象.
作者:
王渠
时间:
2012-8-1 13:30
本帖最后由 王渠 于 2012-8-1 13:34 编辑
HashSet:是Map的实例,这点可以从java源文件中看到,从api中,可以看到,map想要遍历,需要转换成set再遍历,也可以看出。
hashset存储的数据结构,是哈希表,而哈希表是由哈希算法计算而得,计算机系统中有自己的哈希值,计算方法,hashcode方法调用的,就是计算机系统自己的哈希值计算方法,计算的。存储元素的唯一性,由hashcode和equals两个方法共同维护,当hashcode方法判断到哈希值相等时,再判断equals方法,当都相等时,判定元素已存在。
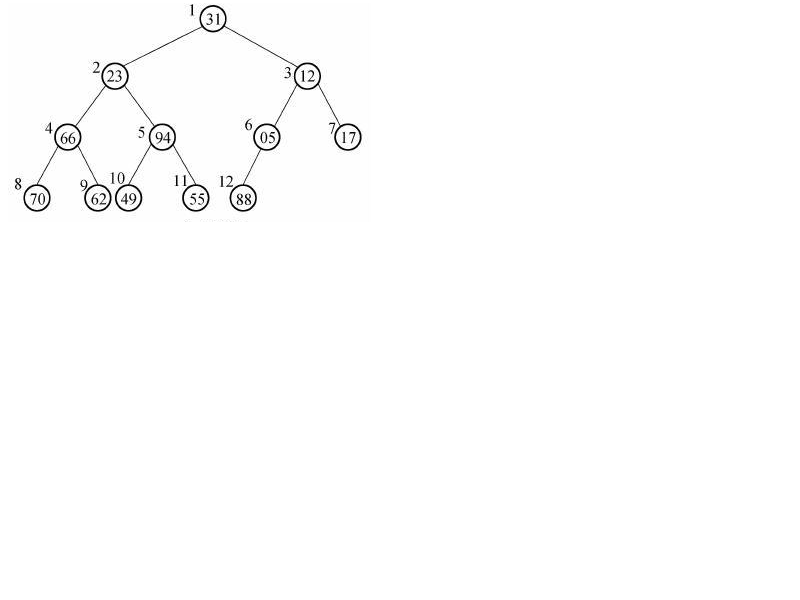
TreeSet:首先它是有序的,并不是无序的。因为它已经继承了comparator接口,从而可以自然排序。TreeSet存储的数据结构是二叉树,这一点就需求存储元素必须是唯一的。
存储的第一个值,为顶部,第二个和顶部compare,得到大小,大在左边,小则放在右边,第三个值,也要按照这样的规则排放,每个新添加进来的元素,必须要放在树的最底层,否则还要跟其他元素compare比较,得出大小,再确定该放在什么位置。
两者的区别还是蛮大的,存放的数据结构不同,这样就是非常大的差别。二叉树,因为null不可以比较,所以不允许存在于TreeSet中。null却可以称为hashSet的值。
hashSet在内存中存放元素其实是无序的,因为计算出来的值是无序的。而TreeSet本身就可以为有序。
图片是网上找的,希望能有帮助,但是没有画出具体的存放规则。圆圈旁边的数字是指第几个存放的。
作者:
pphdsny3
时间:
2012-8-1 13:39
这是别人的回答,我感觉还不错,楼主可以借鉴下!
==========================他们的区别===========================
HashSet无序
TreeSet有序
二者里边不能有重复的对象
1. HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key
2. Map的key和Set都有一个共同的特性就是集合的唯一性.TreeMap更是多了一个排序的功能.
3. hashCode和equal()是HashMap用的, 因为无需排序所以只需要关注定位和唯一性即可.
a. hashCode是用来计算hash值的,hash值是用来确定hash表索引的.
b. hash表中的一个索引处存放的是一张链表, 所以还要通过equal方法循环比较链上的每一个对象
才可以真正定位到键值对应的Entry.
c. put时,如果hash表中没定位到,就在链表前加一个Entry,如果定位到了,则更换Entry中的value,并返回旧value
4. 由于TreeMap需要排序,所以需要一个Comparator为键值进行大小比较.当然也是用Comparator定位的.
a. Comparator可以在创建TreeMap时指定
b. 如果创建时没有确定,那么就会使用key.compareTo()方法,这就要求key必须实现Comparable接口.
c. TreeMap是使用Tree数据结构实现的,所以使用compare接口就可以完成定位了.
=====================================他们的用法======================
HashSet的使用
import java.util.HashSet;
import java.util.Iterator;
public class WpsklHashSet
{
//java 中Set的使用(不允许有重复的对象):
public static void main(String[] args)
{
HashSet hashSet=new HashSet();
String a=new String("A");
String b=new String("B");
String c=new String("B");
hashSet.add(a);
hashSet.add(b);
System.out.println(hashSet.size());
String cz=hashSet.add(c)?"此对象不存在":"已经存在";
System.out.println("测试是否可以添加对象 "+cz);
System.out.println(hashSet.isEmpty());
//测试其中是否已经包含某个对象
System.out.println(hashSet.contains("A"));
Iterator ir=hashSet.iterator();
while(ir.hasNext())
{
System.out.println(ir.next());
}
//测试某个对象是否可以删除
System.out.println(hashSet.remove("a"));
System.out.println(hashSet.remove("A"));
//经过测试,如果你想再次使用ir变量,必须重新更新以下
ir=hashSet.iterator();
while(ir.hasNext())
{
System.out.println(ir.next());
}
}
}
/**
* 通过这个程序,还可以测试树集的添加元素的无序性与输出的有序性
*/
import java.util.TreeSet;
import java.util.Iterator;
public class TreeSetTest
{
public static void main(String[] args)
{
TreeSet tree = new TreeSet();
tree.add("China");
tree.add("America");
tree.add("Japan");
tree.add("Chinese");
Iterator iter = tree.iterator();
while(iter.hasNext())
{
System.out.println(iter.next());
}
}
}
以上就是他们的区别和用法,重在理解,多用,祝你成功
作者:
杨康
时间:
2012-8-1 14:01
HashSet底层数据结构是哈希表,通过一定的算法,得到的哈希值按照一定的顺序组成了哈希表,因为每个对象的哈希值不同,有可能第一个存入的对象的哈希值比后存入的对象的哈希值大,这种情况下,第一个存入的对象就排在其他比它哈希值小的后面,这就是为什么HashSet是无序的原因.
而实现情况,存入对象的时候,系统自动调用该集合的hashCode()方法来判断两个哈希值是否相等,如果不想等,判断结果为两个不同对象,不会调用equals()方法.如果不想等,则会继续调用equals()方法来做更深层次的判断两个对象是否是同一个对象.这就是为什么用HashSet集合存储自定义对象的时候必须复写hashCode()方法和equals()方法.
TreeSet底层数据结构是二叉树,判断是否是同一元素并排序的方法是compareTo()的返回值,图示如三楼的图.如果返回值是一个正数,则表示该对象大于传入对象,所以传入对象应放在该对象的左边.同理,小于0就放在该对象的右边.当出现等于0的情况时,需要自己定义深层判断对象相等的依据一遍判断对象是否是同一对象.
以上是我自己对该两种集合的理解,不完整或者不对的地方请见谅.
欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/)
黑马程序员IT技术论坛 X3.2