黑马程序员技术交流社区
标题:
如何用Java写一个知乎爬虫?
[打印本页]
作者:
jacobsnow
时间:
2016-5-1 15:40
标题:
如何用Java写一个知乎爬虫?
如何用Java写一个知乎爬虫?
老夏
,发源地大数据交易平台
这里,耗费了不少的业余时间,专门为爬虫入门或初中级写了一个知乎爬虫。为什么选择知乎呢?应为这里例子可以尽量多的将爬虫涉及的技术点包含进去,同时又不至于那么复杂,学习和提升兼顾。下面说明知乎爬虫的源码和涉及主要技术点:
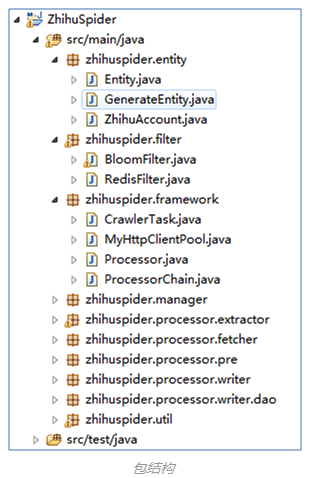
(
1
)程序
package
组织
(
2
)模拟登录(爬虫主要技术点
1
)
要爬去需要登录的网站数据,模拟登录是必要可少的一步,而且往往是难点。知乎爬虫的模拟登录可以做一个很好的案例。要实现一个网站的模拟登录,需要两大步骤是:(1)对登录的请求过程进行分析,找到登录的关键请求和步骤,分析工具可以有IE自带(快捷键F12)、Fiddler、HttpWatcher;(2)编写代码模拟登录的过程。
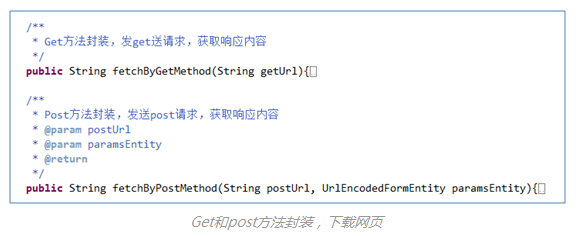
(
3
)网页下载(爬虫主要技术点
2
)
模拟登录后,便可下载目标网页html了。知乎爬虫基于HttpClient写了一个网络连接线程池,并且封装了常用的get和post两种网页下载的方法。
(
4
)自动获取网页编码(爬虫主要技术点
3
)
自动获取网页编码是确保下载网页html不出现乱码的前提。知乎爬虫中提供方法可以解决绝大部分乱码下载网页乱码问题。
(
5
)网页解析和提取(爬虫主要技术点
4
)
使用Java写爬虫,常见的网页解析和提取方法有两种:利用开源Jar包Jsoup和正则。一般来说,Jsoup就可以解决问题,极少出现Jsoup不能解析和提取的情况。Jsoup强大功能,使得解析和提取异常简单。知乎爬虫采用的就是Jsoup。
(
6
)正则匹配与提取(爬虫主要技术点
5
)
虽然知乎爬虫采用Jsoup来进行网页解析,但是仍然封装了正则匹配与提取数据的方法,因为正则还可以做其他的事情,如在知乎爬虫中使用正则来进行url地址的过滤和判断。
(
7
)数据去重(爬虫主要技术点
6
)
对于爬虫,根据场景不同,可以有不同的去重方案。(1)少量数据,比如几万或者十几万条的情况,使用Map或Set便可;(2)中量数据,比如几百万或者上千万,使用BloomFilter(著名的布隆过滤器)可以解决;(3)大量数据,上亿或者几十亿,Redis可以解决。知乎爬虫给出了BloomFilter的实现,但是采用的Redis进行去重。
(
8
)设计模式等
Java
高级编程实践
除了以上爬虫主要的技术点之外,知乎爬虫的实现还涉及多种设计模式,主要有链模式、单例模式、组合模式等,同时还使用了Java反射。除了学习爬虫技术,这对学习设计模式和Java反射机制也是一个不错的案例。
4.
一些抓取结果展示
注:转载自知乎 原帖:https://www.zhihu.com/question/36909173
多看看案例。知道自己学这么东西到底是干什么用的。心里也有目标……
欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/)
黑马程序员IT技术论坛 X3.2
 (2)模拟登录(爬虫主要技术点1)
(2)模拟登录(爬虫主要技术点1)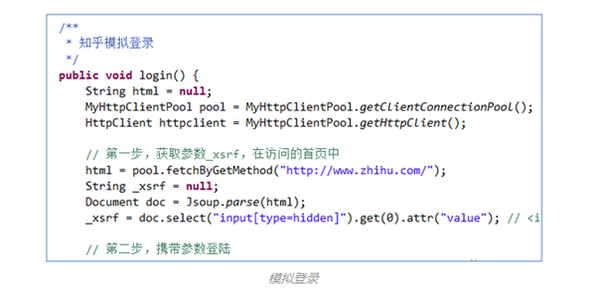 (3)网页下载(爬虫主要技术点2)
(3)网页下载(爬虫主要技术点2)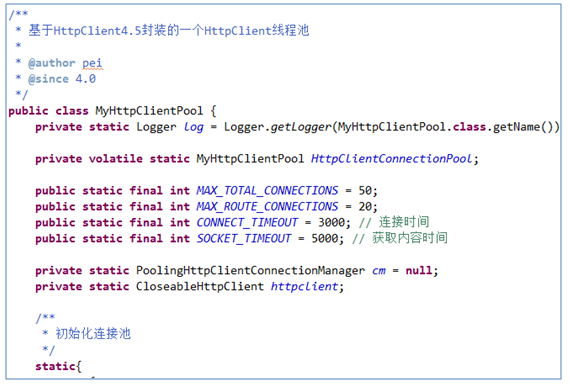
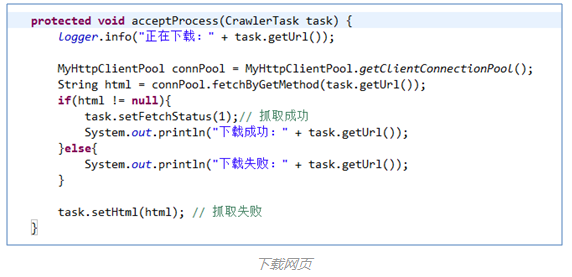 (4)自动获取网页编码(爬虫主要技术点3)
(4)自动获取网页编码(爬虫主要技术点3)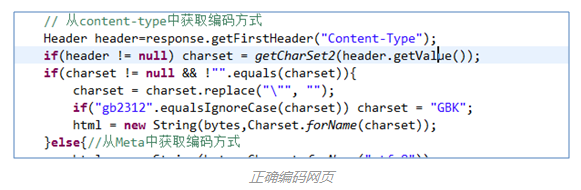 (5)网页解析和提取(爬虫主要技术点4)
(5)网页解析和提取(爬虫主要技术点4)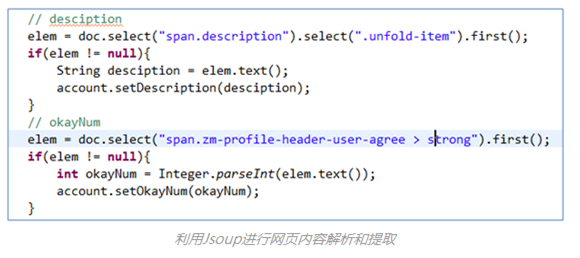 (6)正则匹配与提取(爬虫主要技术点5)
(6)正则匹配与提取(爬虫主要技术点5)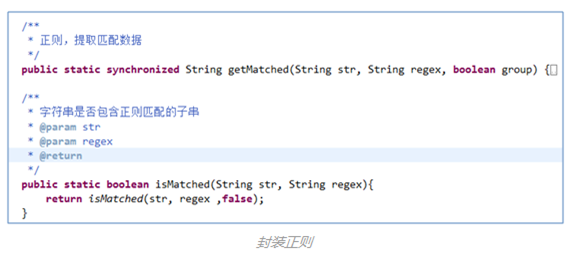 (7)数据去重(爬虫主要技术点6)
(7)数据去重(爬虫主要技术点6)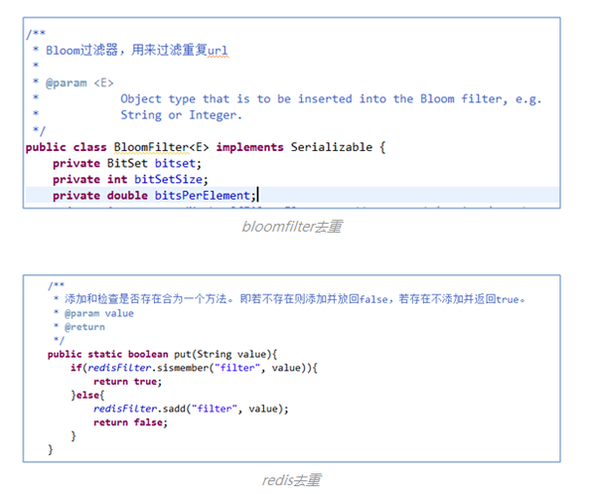 (8)设计模式等Java高级编程实践
(8)设计模式等Java高级编程实践