随着近十年互联网的迅猛发展,越来越多的人融入了互联网——利用搜索引擎查询词条或问题;社交圈子从现实搬到了Facebook、Twitter、微信等社交平台上;女孩子们现在少了逛街,多了在各大电商平台上的购买;喜欢棋牌的人能够在对战平台上找到世界各地的玩家对弈。在国内随着网民数量的持续增加,造成互联网公司的数据在体量、产生速度、多样性等方面呈现出巨大的变化。
互联网产生的数据相较于传统软件产生的数据,有着数据挖掘的巨大潜力。通过对数据的挖掘,可以统计出PV、UV,计算出不同设备与注册率、促销与下单率之间的关系,甚至构建热点分析、人群画像等算法模型,产生一系列报表、图形、离线统计、实时计算的产品。互联网公司如果能有效利用这些数据,将对决策和战略发展起到至关重要的作用。
在大数据的大势之下,Hadoop、Spark、Flink、Storm、Dremel、Impala、Tez等一系列大数据技术如雨后春笋般不断涌现。工程师们正在使用这些工具在摸索中前行。
Spark是一个通用的并行计算框架,由加州伯克利大学(UCBerkeley)的AMP实验室开发于2009年,并于2010年开源。2013年成长为Apache旗下在大数据领域最活跃的开源项目之一。
Spark目前已经走过了0.x和1.x两个时代,现在正在2.x时代稳步发展。Spark从2012年10月15日发布0.6到2016年1月4日发布1.6只经过了三年时间,那时候差不多每个月都会有新的版本发布,平均每个季度会发布一个新的二级版本。
自从2016年7月发布了2.0.0版本以来,只在当年12月又发布了2.1.0版本,直到目前为止还没有新的二级版本发布。Spark发布新版本的节奏明显慢了下来,当然这也跟Spark团队过于激进的决策(比如很多API不能向前兼容,让用户无力吐槽)有关。
Spark也是基于map reduce 算法模型实现的分布式计算框架,拥有Hadoop MapReduce所具有的优点,并且解决了Hadoop MapReduce中的诸多缺陷。
Hadoop MRv1的局限早在Hadoop1.0版本,当时采用的是MRv1版本的MapReduce编程模型。MRv1版本的实现都封装在org.apache.hadoop.mapred包中,MRv1的Map和Reduce是通过接口实现的。MRv1包括三个部分:
MRv1存在以下不足。
MRv1的示意如图1。
图1 MRv1示意图
Apache为了解决以上问题,对Hadoop升级改造,MRv2最终诞生了。MRv2中,重用了MRv1中的编程模型和数据处理引擎。但是运行时环境被重构了。JobTracker被拆分成了通用的资源调度平台(ResourceManager,简称RM)、节点管理器(NodeManager)和负责各个计算框架的任务调度模型(ApplicationMaster,简称AM)。ResourceManager依然负责对整个集群的资源管理,但是在任务资源的调度方面只负责将资源封装为Container分配给ApplicationMaster 的一级调度,二级调度的细节将交给ApplicationMaster去完成,这大大减轻了ResourceManager 的压力,使得ResourceManager 更加轻量。NodeManager负责对单个节点的资源管理,并将资源信息、Container运行状态、健康状况等信息上报给ResourceManager。ResourceManager 为了保证Container的利用率,会监控Container,如果Container未在有限的时间内使用,ResourceManager将命令NodeManager杀死Container,以便于将资源分配给其他任务。MRv2的核心不再是MapReduce框架,而是Yarn。在以Yarn为核心的MRv2中,MapReduce框架是可插拔的,完全可以替换为其他MapReduce实现,比如Spark、Storm等。MRv2的示意如图2所示。
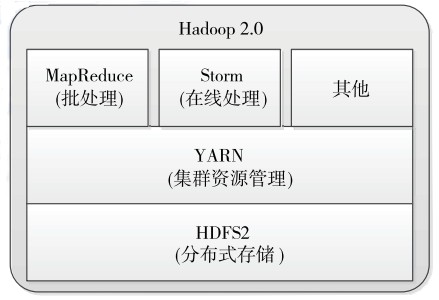
图2 MRv2示意图
Hadoop MRv2虽然解决了MRv1中的一些问题,但是由于对HDFS的频繁操作(包括计算结果持久化、数据备份、资源下载及Shuffle等)导致磁盘I/O成为系统性能的瓶颈,因此只适用于离线数据处理或批处理,而不能支持对迭代式、流式数据的处理。
Spark的特点Spark看到MRv2的问题,对MapReduce做了大量优化,总结如下:
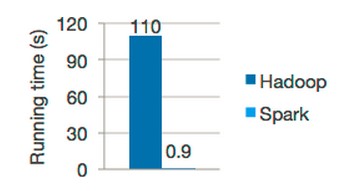
基于以上所列举的优化,Spark官网声称性能比Hadoop快100倍,如图3所示。即便是内存不足需要磁盘I/O时,其速度也是Hadoop的10倍以上。
图3 Hadoop与Spark执行逻辑回归时间比较
Spark还有其他一些特点。
Hadoop常用于解决高吞吐、批量处理的业务场景,例如对浏览量的离线统计。如果需要实时查看浏览量统计信息,Hadoop显然不符合这样的要求。Spark通过内存计算能力极大地提高了大数据处理速度,满足了以上场景的需要。此外,Spark还支持交互式查询,SQL查询,流式计算,图计算,机器学习等。通过对Java、Python、Scala、R等语言的支持,极大地方便了用户的使用。
笔者就目前所知道的Spark应用场景,进行介绍。
1.医疗健康看病是一个非常典型的分析过程——医生根据患者的一些征兆、检验结果,结合医生本人的经验得出结论,最后给出相应的治疗方案。现在国内的医疗状况是各地区医疗水平参差不齐,医疗资源也非常紧张,特别是高水平医生更为紧缺,好医院的地区分布很不均衡。大城市有更完善的医疗体系,而农村可能就只有几个赤脚医生。一些农民看病可能要从村里坐车到镇,再到县城,再到地级市甚至省会城市,看病的路程堪比征程。
大数据根据患者的患病征兆、检验报告,通过病理分析模型找出病因并给出具体的治疗方案。即便是医疗水平落后的地区,只需要输入患者的患病征兆和病例数据既可体验高水平医师的服务。通过Spark从海量数据中实时计算出病因,各个地区的医疗水平和效率将获得大幅度提升,同时也能很好的降低因为医生水平而导致误诊的概率。
实施医疗健康的必然措施是监测和预测。通过监测不断更新整个医疗基础库的知识,并通过医疗健康模型预测出疾病易发的地区和人群。
2.电商通过对用户的消费习惯、季节、产品使用周期等数据的收集,建立算法模型来判断消费者未来一个月、几个月甚至一年的消费需求(不是简单的根据你已经消费的产品,显示推荐广告位),进而提高订单转化率。
在市场营销方面,通过给买家打标签,构建人群画像,进而针对不同的人群,精准投放广告、红包或优惠券。
3.安全领域面对日益复杂的网络安全,通过检测和数据分析区分出不同的安全类型。并针对不同的安全类型,实施不同的防御、打击措施。
构建金融云,通过对巨量的计量数据收集。通过Spark实时处理分析,利用低延迟的数据处理能力,应对急迫的业务需求和数据增长。
量化投资——收集大宗商品的价格,黄金,石油等各种数据,分析黄金、股票等指数趋势,支持投资决策。
除了以上领域外,在搜索引擎、生态圈异常检测、生物计算等诸多领域都有广泛的应用场景。
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |