黑马程序员技术交流社区
标题: 【上海校区】TensorFlow实现自编码器 [打印本页]
作者: 梦缠绕的时候 时间: 2018-6-26 09:49
标题: 【上海校区】TensorFlow实现自编码器
1、什么是自编码器
自编码器(Autoencoder,AE),是一种利用反向传播算法使得输出值等于输入值的神经网络,自动编码器内部有一个隐含层h,可以产生编码来表示输入。它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。自编码器由两部分组成:
编码器:这部分能将输入压缩成潜在空间表征,可以用编码函数h=f(x)表示。
解码器:这部分能重构来自潜在空间表征的输入,可以用解码函数r=g(h)表示。
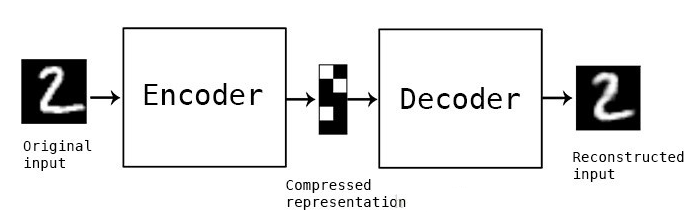
因此,整个自编码器可以用函数g(f(x)) = r来描述,其中输出r与原始输入x相近。为何要用输入来重构输出?如果自编码器的唯一目的是让输出值等于输入值,那这个算法将毫无用处。事实上,我们希望通过训练输出值等于输入值的自编码器,让潜在表征将具有价值属性。这可通过在重构任务中构建约束来实现。
从自编码器获得有用特征的一种方法是,限制隐层h的维度使其小于输入x,这种情况下称作有损自编码器。通过训练有损表征,使得自编码器能学习到数据中最重要的特征。如果自编码器的容量过大,它无需提取关于数据分布的任何有用信息,即可较好地执行重构任务。如果潜在表征h的维度与输入相同,或是潜在表征h的维度大于输入,上述结果也会出现。在这些情况下,即使只使用线性编码器和线性解码器,也能很好地利用输入重构输出,且无需了解有关数据分布的任何有用信息。在理想情况下,根据要分配的数据复杂度,来准确选择编码器和解码器的编码维数和容量,就可以成功地训练出任何所需的自编码器结构。
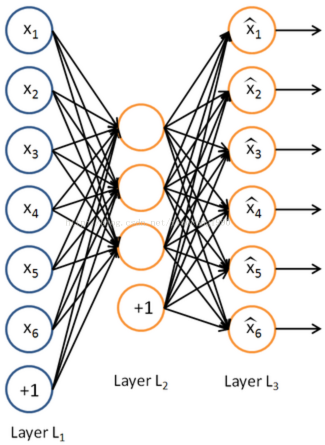
这个图就是稀疏自编码器的样例,Layer L1是输入层,Layer L3是输出层,Layer L2是隐藏层h。
2、自编码器用来干什么?
目前,自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。设置合适的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
自编码器能从数据样本中进行无监督学习,这意味着可将这个算法应用到某个数据集中,来取得良好的性能,且不需要任何新的特征工程,只需要适当地训练数据。但是,自编码器在图像压缩方面表现得不好。由于在某个给定数据集上训练自编码器,因此它在处理与训练集相类似的数据时可达到合理的压缩结果,但是在压缩差异较大的其他图像时效果不佳。这里,像JPEG这样的压缩技术在通用图像压缩方面会表现得更好。训练自编码器,可以使输入通过编码器和解码器后,保留尽可能多的信息,但也可以训练自编码器来使新表征具有多种不同的属性。不同类型的自编码器旨在实现不同类型的属性。
3、自编码器分类
(1)去噪自动编码器(DAE/Denoising AutoEncoder)
(2)稀疏自动编码器
(3)变分自动编码器(VAE/Variational AutoEncoder)
(4)收缩自动编码器(CAE/Contractive AutoEncoder)
去噪自动编码器:这是最基本的一种自动编码器,它会随机地部分采用受损的输入来解决恒等函数风险,使得自动编码器必须进行恢复或去噪。这项技术可用于得到输入的良好表征。良好的表征是指可以从受损的输入稳健地获得的表征,该表征可被用于恢复其对应的无噪声输入。去噪自动编码器背后的思想很简单。为了迫使隐藏层发现更加稳健的特征并且为了防止其只是学习其中的恒等关系,我们在训练自动编码器时会让其从受损的版本中重建输入。应用在输入上的噪声量以百分比的形式呈现。一般来说,30%或0.3就很好,但如果你的数据非常少,你可能就需要考虑增加更多噪声。
4、去噪自编码器的实现
实现自编码器和实现一个单隐含层的神经网络差不多,只不过是在数据输入时做了标准化,并加上一个高斯噪声,同时我们的输出结果不是数字分类结果,而是复原的数据,因此不需要用标注过的数据进行监督训练。自编码器作为一种无监督学习,它不是对数据进行聚类,而是提取其中最有用、最频繁出现的高阶特征,根据这些高阶特征重构数据。
[python] view plain copy
- #coding=utf-8
- import numpy as np
- import sklearn.preprocessing as prep
- import tensorflow as tf
- import pickle
-
- # 定义一个mnist数据集的类
- class mnistReader():
- def __init__(self,mnistPath,onehot=True):
- self.mnistPath=mnistPath
- self.onehot=onehot
- self.batch_index=0
- print ('read:',self.mnistPath)
- fo = open(self.mnistPath, 'rb')
- self.train_set,self.valid_set,self.test_set = pickle.load(fo,encoding='bytes')
- fo.close()
- self.data_label_train=list(zip(self.train_set[0],self.train_set[1]))
- np.random.shuffle(self.data_label_train)
-
- # 获取训练集合测试集
- def get_train_test_image(self):
- return self.train_set[0],self.test_set[0]
-
- # Xavier初始化器会根据某一层网络的输入、输出节点数量自动调整最合适的分布
- def xavier_init(fan_in,fan_out,constant=1):
- '''''
- fan_in:输入节点的数量
- fan_out:输出节点的数量
- '''
- low=-constant*np.sqrt(6.0/(fan_in+fan_out))
- high=constant*np.sqrt(6.0/(fan_in+fan_out))
- return tf.random_uniform(shape=(fan_in,fan_out),minval=low,maxval=high,dtype=tf.float32)
- '''''
- 函数tf.random_uniform:
- 生成的值在该 [minval, maxval) 范围内遵循均匀分布。下限 minval 包含在范围内,而上限 maxval 被排除在外。
- shape是张量的大小
- '''
-
- # 定义去噪自编码器的类
- class AdditiveGaussianNoiseAutoencoder(object):
-
- def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,optimizer=tf.train.AdamOptimizer,scale=0.1):
- self.n_input=n_input # 输入变量数
- self.n_hidden=n_hidden # 隐层节点数
- self.transfer=transfer_function # 隐层的激活函数,默认为softplus
- self.scale=tf.placeholder(tf.float32) # 噪声的百分比
- self.training_scale=scale
- network_weights=self._initialize_weights() # 初始化权重
- self.weights=network_weights
-
- # 定义输入层、隐藏层、重建层
- self.x=tf.placeholder(tf.float32,[None,self.n_input])
- self.hidden=self.transfer(tf.add(tf.matmul(self.x+scale*tf.random_normal((n_input,)),self.weights['w1']),self.weights['b1']))
- self.reconstruction=tf.add(tf.matmul(self.hidden,self.weights['w2']),self.weights['b2'])
-
- # 定义自编码器的损失函数,这里使用平方误差
- self.cost=0.5*tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction,self.x),2.0))
- self.optimizer=optimizer.minimize(self.cost)
-
- # 创建session,全局变量初始化
- init=tf.global_variables_initializer()
- self.sess=tf.Session()
- self.sess.run(init)
-
- # 定义权重初始化函数
- def _initialize_weights(self):
- all_weights=dict()
- all_weights['w1']=tf.Variable(xavier_init(self.n_input,self.n_hidden))
- all_weights['b1']=tf.Variable(tf.zeros([self.n_hidden],dtype=tf.float32))
- all_weights['w2']=tf.Variable(tf.zeros([self.n_hidden,self.n_input],dtype=tf.float32))
- all_weights['b2']=tf.Variable(tf.zeros([self.n_input],dtype=tf.float32))
- return all_weights
-
- # 定义计算损失cost及执行一步训练的函数
- def partial_fit(self,x):
- cost,opt=self.sess.run((self.cost,self.optimizer),feed_dict={self.x:x,self.scale:self.training_scale})
- return cost
-
- # 定义一直只求损失的函数,用于测试集
- def calc_total_cost(self,x):
- return self.sess.run(self.cost,feed_dict={self.x:x,self.scale:self.training_scale})
-
- # 定义返回编码器隐藏层的输出结果
- def transform(self,x):
- return self.sess.run(self.hidden,feed_dict={self.x:x,self.scale:self.training_scale})
-
- # 定义输出层的结果,隐藏层作为输入
- def generate(self,hidden=None):
- if hidden is None:
- hidden=np.random.normal(size=self.weights['b1'])
- return self.sess.run(self.reconstruction,feed_dict={self.hidden:hidden})
-
- # 定义重建函数,它整体运行一遍复原过程
- def reconstruct(self,x):
- return self.sess.run(self.reconstruction,feed_dict={self.x:x,self.scale:self.training_scale})
-
- # 定义获取隐含层权重的函数
- def getWeights(self):
- return self.sess.run(self.weights['w1'])
-
- #定义获得隐层偏置的函数
- def getBiases(self):
- return self.sess.run(self.weights['b1'])
-
- # 定义对训练和测试数据进行标准化处理的函数,标准化即让数据变成0均值,标准差为1的分布
- def standard_scale(X_train,X_test):
- preprocessor=prep.StandardScaler().fit(X_train)
- X_train=preprocessor.transform(X_train)
- X_test=preprocessor.transform(X_test)
- return X_train,X_test
-
- # 定义一个获取随机块数据的函数,取一个从0到len(data) - batch_size之间的随机整数
- def get_random_block_from_data(data,batch_size):
- start_index=np.random.randint(0,len(data)-batch_size)
- return data[start_index:(start_index+batch_size)]
-
- # 程序运行
- if __name__ == '__main__':
- print ("begin train...")
-
- mnist=mnistReader(mnistPath="E:/testdata/mnist.pkl")
- train,test=mnist.get_train_test_image()
-
- X_train,X_test=standard_scale(train,test) # 获得标准化后的训练集和测试集
- n_samples=int(len(train)) # 训练集的样本总数
- train_epoches=20 # 迭代次数
- batch_size=128 # 块大小
- display_step=1 # 显示间隔
-
- # 初始化自编码器
- autocoder=AdditiveGaussianNoiseAutoencoder(n_input=784,n_hidden=200,transfer_function=tf.nn.softplus,optimizer=tf.train.AdamOptimizer(learning_rate=0.001),scale=0.01)
- # 开始训练
- for epoch in range(train_epoches):
- avg_cost=0
- total_batch=int(n_samples/batch_size)
- for i in range(total_batch):
- batch_xs=get_random_block_from_data(X_train,batch_size)
- cost=autocoder.partial_fit(batch_xs)
- avg_cost+=cost/n_samples*batch_size
- if epoch%display_step==0:
- print ("epoch:",'%04d'%(epoch+1),"cost=","{:.9f}".format(avg_cost))
-
- # 显示总的成本
- print ("total cost:"+str(autocoder.calc_total_cost(X_test)))
作者: 吴琼老师 时间: 2018-7-5 16:45

| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) |
黑马程序员IT技术论坛 X3.2 |