黑马程序员技术交流社区
标题: 【上海校区】Python学习-KNN预测加尼福尼亚房价 [打印本页]
作者: 不二晨 时间: 2018-6-29 09:48
标题: 【上海校区】Python学习-KNN预测加尼福尼亚房价
加尼福尼亚房价数据集与KNN
需要的几个Python库
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.neighbors import KNeighborsRegressor
from sklearn.cross_validation import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
数据集内容:

这里data为数据集,target为目标,DESCR为简单的介绍,feature_names为列名。
利用train_test_split函数对训练和测试集进行划分
cali=datasets.california_housing.fetch_california_housing()
x=cali['data']
y=cali['target']
#x=pd.DataFrame(x)
#x.columns=cali['feature_names']
x_train,x_test,y_train,y_test=train_test_split(x,y,train_size=0.8)
这里是sklearn-train_test_split随机划分的介绍:
传送门: https://blog.csdn.net/cherdw/article/details/54881167
我就直接截图贴在这里了:

KNN在分类过程中近需要在训练集中寻找最近的前K个样本,然后给定K个最相似的样本,出现最多的目标标号被选为分类标号。在使用此聚类时,近邻数目(K)和估计相似度的度量需要给定。KNN在处理小数据集时非常好,但是并不适合处理大数据集。(摘自《数据科学导论》)
在这里,KNN就是根据样本集的各个特征的欧式距离进行划分。
在用KNN预测前,需要将源数据标准化
因为KNN是基于欧式距离的聚类,如果不同特征因为数值的差异造成不同特征的影响差距很大,所以需要进行数据标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
x_train_scaled=scaler.fit_transform(x_train)
x_test_scaled=scaler.transform(x_test)
regressor=KNeighborsRegressor()
regressor.fit(x_train_scaled,y_train)
y_pred=regressor.predict(x_test_scaled)
print ("MAE=",mean_squared_error(y_test,y_pred))
MAE为平均绝对误差,它的值越小表示预测结果越精确。
这里的结果是0.39。而没做标准化的结果是1.14。显然标准化后的结果更好。
结果截图:
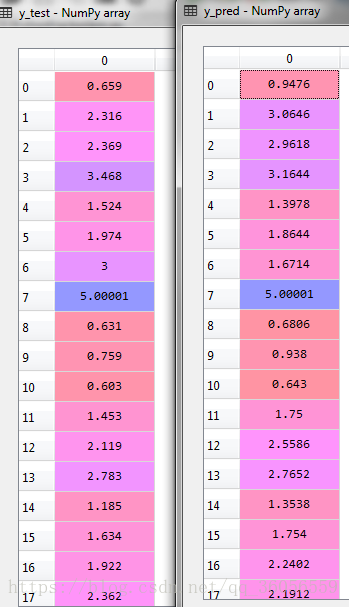
这里还有一个类似的例子
KNN预测电影类型的传送门:https://blog.csdn.net/saltriver/article/details/52502253
参考资料:《数据科学导论》
【转载】原文地址:https://blog.csdn.net/qq_36056559/article/details/80728591
作者: 吴琼老师 时间: 2018-7-5 16:43

| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) |
黑马程序员IT技术论坛 X3.2 |