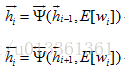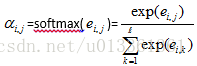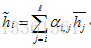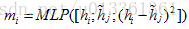
释义识别概念
1、两个问题具有相同的语义(二分类),即如果两个问题的回答完全相同,那么这两个问题是相互释义的。
2、检验检索出来的问题是否是一个输入问题的释义。
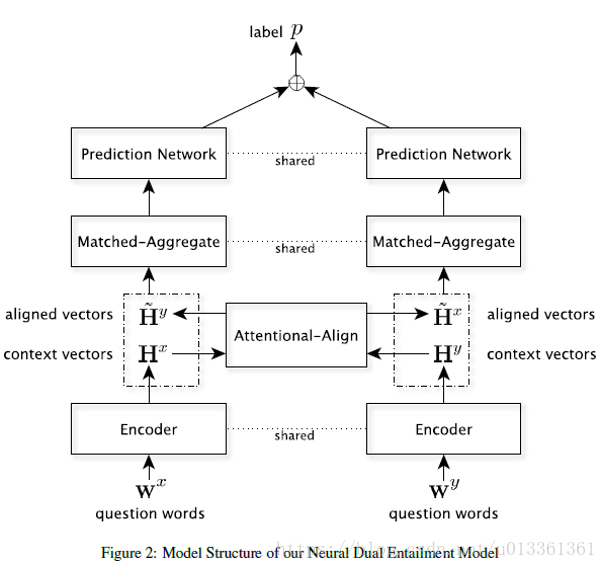
模型架构
模型分为四部分:编码器、注意力对齐、匹配聚合、双预测网络。该模型利用双向递归神经网络将前提问题编码为短语向量,然后利用注意机制从候选问题中提取软对齐的对应短语嵌入。
最后的相似性得分是基于两个蕴涵方向的聚合短语比较来产生的。
模型是对称的,且参数对于两侧是共享的。即使在中等大小的数据集上也可以有效训练模型参数。
问题数学表达
假如有两个问题句子A和B,A表示为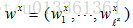
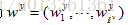
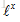
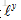
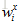
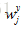
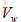
训练集由标签文本对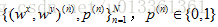
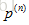
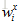
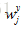
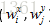
一、编码器
目的:获取每个单词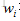
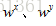
1. 利用混合嵌入矩阵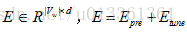
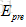
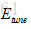
混合设置的目的是:对嵌入做fine-tune,避免过早偏离预先训练的表示,以识别特定领域的词义语义。
2 .编码器将词嵌入序列转换成上下文向量列表H=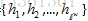
由两层堆叠双向循环神经网络(BRNN)利用两边的上下文构成。BRNN编码器从两个方向用两个分开的隐藏子层处理数据。表示成:
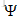
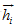
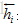
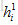
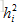
二、注意力对齐
目的:从另一个句子的编码序列 中收集一个软对齐上下文向量。
1. 计算每对上下文向量基于内容的得分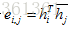
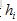
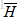
2. 对相关性得分进行归一化,作为注意力权重。
3. 生成软对齐短语向量,是注意力权重和上下文向量的加权和.
三、匹配聚合
给定H和它的软对齐向量
每对对齐向量首先被合并成一个匹配向量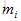
四、双预测网络
预测网络由两层批处理归一化多层感知机,MaxOut神经元网络,和基于上述匹配聚合向量产生蕴含得分的线性层构成。然而,注意对齐、匹配聚合、预测网络只能检查一个句子的信息是否被另一个句子所覆盖。为了识别释义,我们使用共享网络从两个方向的问题对去计算蕴涵得分。最后,将两个分数相加,然后用Logistic层预测标签P。
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |