黑马程序员技术交流社区
标题: 【上海校区】机器学习小实战(四) KMeans聚类 [打印本页]
作者: 不二晨 时间: 2018-8-2 15:10
标题: 【上海校区】机器学习小实战(四) KMeans聚类
一、 KMeans聚类简介需要事先指定簇的数目k
优化目标:所有点到各自质心的距离之和最小
特点:受初始值(K个随机质心的位置)的影响挺大的、受形状的影响还有点大
二、小案例读数据、算法实例化(设置参数),训练模型、展示与分析
1. 读取数据,了解一下
import numpy as np
import pandas as pd
import matplotlib as plt
beer=pd.read_csv('data.txt',sep=' ')
print(beer.shape) #(20, 5)
print(beer.head())

2. 数据预处理
给定数据集有5列,第一列是名字,与特征没什么关系,所以将后面四列提取出来,作为接下来聚类的数据。
X=beer[['calories','sodium','alcohol','cost']]3. KMeans聚类算法
算法实例化:指定簇的个数为3或2,然后将数据传入进行训练
from sklearn.cluster import KMeans
km_3=KMeans(n_clusters=3).fit(X) #一行完成算法的实例化和传入数据
km_2=KMeans(n_clusters=2).fit(X)
km_3.labels_
结果:array([0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 0, 2, 0, 0, 0, 1, 0, 0, 1, 2])
输出的这个数组中有3种取值:0,1,2对应三个不同的簇的标签
beer['cluster_3']=km_3.labels_ #将标签值(所在的是哪个簇)作为新的特征存入csv中
beer['cluster_2']=km_2.labels_
beer.sort_values('cluster_3') #按值内容排序

4. 结果可视化
多个特征,做二维可视化时就只能选择2个特征进行可视化咯
from pandas.tools.plotting import scatter_matrix #散布图矩阵
cluster_centers3=km_3.cluster_centers_
cluster_centers2=km_2.cluster_centers_
beer.groupby('cluster_3').mean() #计算不同类别所对应的其他属性的平均值
beer.groupby('cluster_2').mean()
centers=beer.groupby('cluster_3').mean().reset_index()
plt.rcParams['font.size']=14
colors=np.array(['red','green','blue','yello'])
#散点图中,两个坐标分别是calories和alcohol的取值
plt.scatter(beer['calories'],beer['alcohol'],c=colors[beer['cluster_3']])
plt.scatter(centers.calories,centers.alcohol,linewidth=3,marker='+',s=300,c='black')
plt.xlabel('calories')
plt.ylabel('alcohol')
结果:centers长啥样——
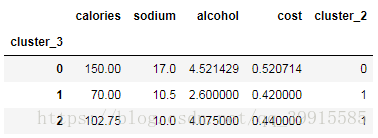

四、 KMeans用于图像压缩1. 读取图像
# -*- coding:utf-8 -*-这行太重要了,在anaconda编程时,要是忘记加上这行,可就显示不出图像了呢
# -*- coding:utf-8 -*-
from skimage import io
from sklearn.cluster import KMeans
import numpy as np
image=io.imread('img.jpg')
io.imshow(image)
io.show()
#print(image.shape) #(647, 650, 3) 原来3个通道

2. KMeans压缩
rows=image.shape[0]
cols=image.shape[1]
image=image.reshape(image.shape[0]*image.shape[1],3) #一张图的像素点排成一列,3表示3个通道的值
kmeans=KMeans(n_clusters=128,n_init=10,max_iter=200) #实例化kmeass,指定n为128(原来是256,并且还有3个通道呢)
kmeans.fit(image) # 实例化kmeans后,传入对象image
clusters=np.asarray(kmeans.cluster_centers_,dtype=np.uint8)#把聚类之后的中心给取出来
labels=np.asarray(kmeans.labels_,dtype=np.uint8)
labels=labels.reshape(rows,cols)#变成二维的了,所以是灰度图形式
print(clusters.shape) #(128, 3)
np.save('codebook_test.npy',clusters)
io.imsave('compressed_test.jpg',labels)
3. 保存与显示
image=io.imread('compressed_test.jpg')
io.imshow(image)
io.show()

太吓人了!!!
作者: 梦缠绕的时候 时间: 2018-8-2 16:22

作者: 不二晨 时间: 2018-8-2 17:32
奈斯,棒棒哒
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) |
黑马程序员IT技术论坛 X3.2 |