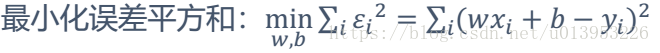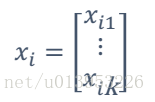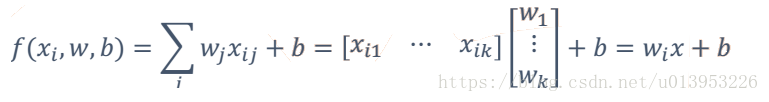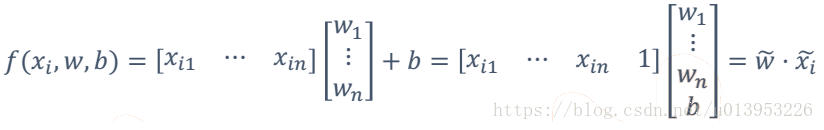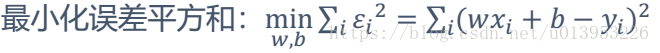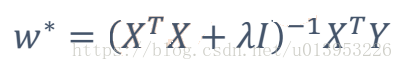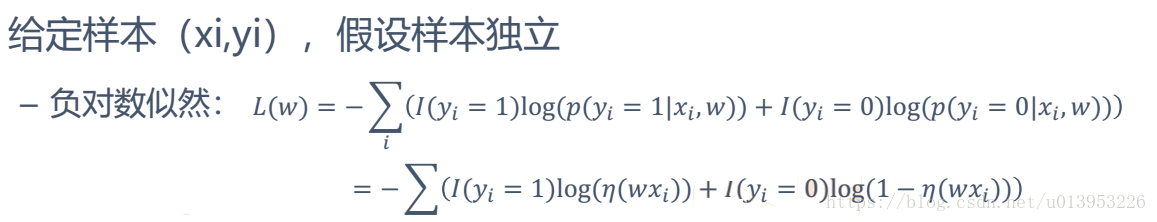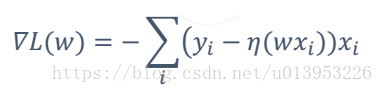
今天进入我们正题,逻辑回归,在讲逻辑回归之前,先来看看线性回归是怎么一回事?
回归抽象成数学中的x和y问题:
x:表示自变量
y:表示因变量
因变量y和自变量x的关系:
-y与x相关:y=f(x,w) w为参数
-y还收到噪音的影响:y=f(x,w) + ε
噪音(ε):就是错误的样本影响后来正确性的判断。
一元线性回归:
输入:一元自变量,一元因变量
--n个样本(x1,y1),.....,(xn,yn) 每一个样本对应一个二维坐标中的一个点也就是一个pair对,因此有多少个样本就有多少个pair对。
回归模型:
-模型输出:y = wx + b
-模型参数:w,b
y=f(x)=wx+b b:控制线的偏移就是偏差
如何学习参数?
回归主要解决两类问题:回归问题和分类中类别概率回归
多元线性回归:
存在多个自变量(向量):
回归公式理解1:
每一个w和x都相乘,最后都相加相当于w和x向量的矩阵做一个乘法,最后加b
有多少个特征就有多少个w
因此我们最关心w , 下面来理解什么是w ?
对于一个人(样本)属性如下:
特征:身高、体重、头发长短
w权重:表示每一个维度特征的权重值 权重范围[0-1] 趋近于0越不重要,趋近于1越不重要
b是偏差、偏置,是一个整体的偏差
身高 0.5 [对应各自的权重]
体重 0.4
头发长度 0.2
肤色 0.1
音色 0.8
假设:一个人(样本)判断是男性/女性
最后的一个分数 score=0.9 thd=0.6[阈值] 0.9>0.6 表示男性 score<0.6 女性
来了一个样本,将样本的里面的所有特征都和权重分别相乘再相加得到一个score,该score判断当前样本的分类问题。
假设,在俄罗斯做一个性别识别模型
b=-0.4 最终加上偏差再去判断当前人的性别
score=0.9 - 0.4 = 男/女
w怎么来?w就是模型 ,回归里面w最重要目的得到 w.
回归公式理解2:统一写为
前面的向量x扩展一个维度,后面向量将b加入到w里面即可。
只需要研究:
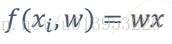
由于在一元回归中最终是求:
求上面公式的最小值,就是对上面的公式进行求导?【求w的导数等于0求极值点】
公式推导:
每一个x相当于是一个特征,y代表所有的标签,
问题:XT * X 不可逆怎么办?
【
1.利用定义,AB=BA=E,如果存在矩阵B,则B为A的可逆矩阵,A就可逆。
2.判断是否为满秩矩阵,若是,则可逆。
3 看这个矩阵的行列式值是够为0,若不为0,则可逆。
4 利用初等矩阵判断,若是初等矩阵,则一定可逆。
】
解决方案:
-设定正数拉姆达:
-拉姆达的值,需要开放测试。
逻辑回归:
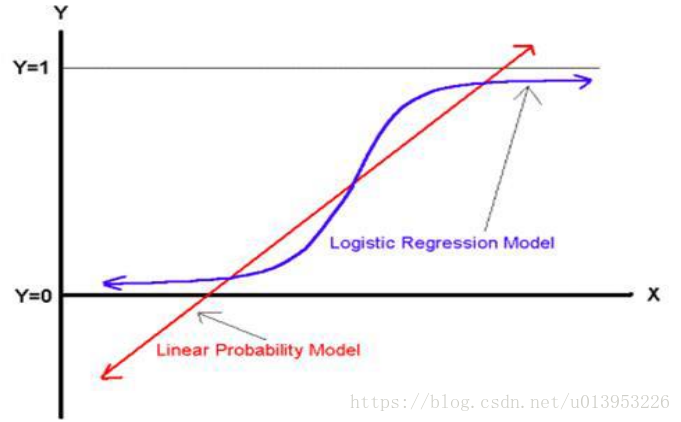
思想:逻辑回归就是在线性回归上加上逻辑判断的过程,主要用于处理分类问题。
因变量y是类比标号{0,1} : 0 :不发生 1:发生
目标:根据特征x,预测发生概率p(y=1|x) :给你一个样本x,你能预测出属于y=1的概率,若概率比较大是男性比较小是女性。
假定p(y=1|x)依赖于线性函数wx
f(x)=p(y=1|x)=wx :其中y=1是一个固定值,x是一个变量,给你一个x,返回一个score
公式推导:
如何计算W 使用了最大似然
最大似然: 当从模型总体随机抽样n组样本观测后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大。
参数理解:
I(yi = 1) : I 表示的是一个符号函数 当这个样本的标签等于1 ,I 就等于1 ,标签不等于 I 就等于0,所以这个符号函数要么等于1或者等于0
【对每一个样本输出的概率全部进行求和】
左边要求所有的样本等于1 ,右边的式子要求所有的样本等于0,等于1 的样本套左边的式子,等于0套右边的式子。
log(p(yj=1 |xi, w )) :log 里面是一个概率值,给你一个样本x ,给你一个参数w ,计算出当前这个样本标签属于1的概率。
由于L(W) 是高阶连续可导的凸函数,根据凸函数理论为了求解最小值【所有等式前面加了一个负号】,可利用梯度下降函数
梯度 :
通俗理解:
5个样本(正、负)
log(p1p2p3p4p5) = score :5个样本同时出现的概率
log(p1)+log(p2)+log(p3)+log(p4)+log(p5) : 表示的是给我一个分数,用来判断当前样本是正或者负
=
I 表示的是一个符号函数 前面三个为正样本 ,后面两个是负样本
I(y=1)(log(p1)+log(p2)+log(p3)+0*log(p3)+0*log(p5)) + I(y=0)(log(p4)+log(p5)+0*log(p1)+0*log(p2)+0*log(p3)
实际应用:
方向导数:某一个方向的导数 在一个二维坐标系中 (x1,y1) (x2,y2) 确定一条线的方向
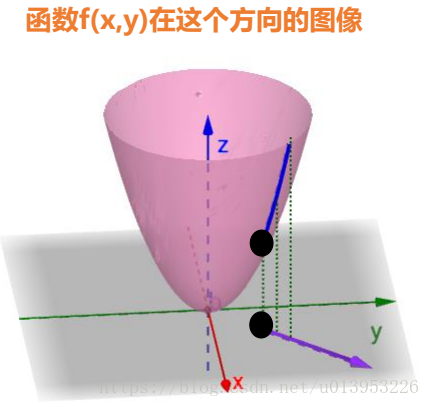
在一个三维坐标上,x,y代表两个维度,z是值域,z=f(x,y) 在这个方向的图像
输入一个x,y,就得到一个值域,x,y有对应的一个点,在碗面上有一个投影点,这个点对应的z值,就是f(x,y)
x,y的方向不一样在碗面的斜率就不一样,代表变化快慢。
函数f(x,y)在A点在这个方向也是有切线的,其切线斜率就是方向导数。
切线方向选择不一样即使步长一样但是,下降的幅度不一样。
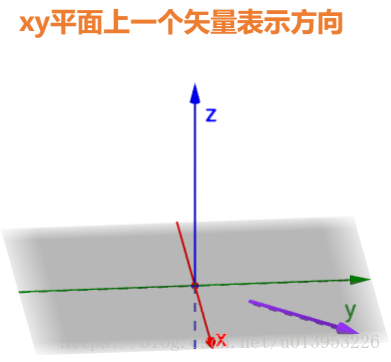
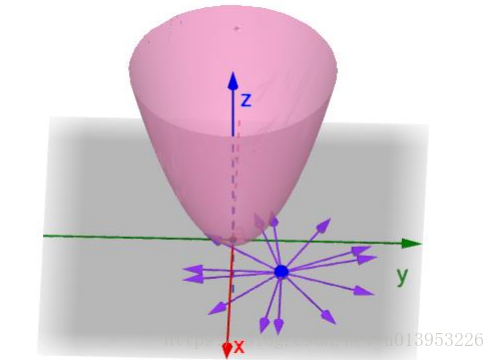
梯度:梯度是一个向量,其方向上的方向导数最大,其大小为此最大方向的导数。
在某一个点上,有很多的方向选择,找到一个方向使得下降速度最快的方向就是他的梯度。
梯度的反方向是下降最快的方向【在方向上变化最快的方向,应该就是上升的方向,若是下降就应该在梯度上加一个负号】。
目标:得到全局最优值,但是,实际往往事与愿违,通常我们得到的只是局部最优值。
梯度下降:
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |