黑马程序员技术交流社区
标题: 【上海校区】生物特征识别技术开发者大赛的baseline [打印本页]
作者: 不二晨 时间: 2018-8-6 09:53
标题: 【上海校区】生物特征识别技术开发者大赛的baseline
训练代码以下是训练代码,直接复制到每一个代码框,按照顺序运行就可以了。
# 下载提交数据的工具!wget -nv -O kesci_submit https://cdn.kesci.com/submit_tool/v1/kesci_submit&&chmod +x kesci_submit# 查看个人持久化工作区文件!ls /home/kesci/work/# 删除训练数据列表!rm -rf /home/kesci/work/first_round_train/# 查看图片import matplotlib.pyplot as pltimg = plt.imread('/mnt/datasets/WebFace/first_round/first_round_train/1505375/016.jpg')plt.figure(1)plt.imshow(img)plt.show()# 查看PaddlePaddle版本!paddle version# 生成图像列表程序import osimport jsonclass CreateDataList: def __init__(self): pass def createTrainDataList(self, data_root_path): # # 把生产的数据列表都放在自己的总类别文件夹中 data_list_path = '' # 所有类别的信息 class_detail = [] # 获取所有类别 class_dirs = os.listdir(data_root_path) # 类别标签 class_label = 0 # 获取总类别的名称 father_paths = data_root_path.split('/') while True: if father_paths[father_paths.__len__() - 1] == '': del father_paths[father_paths.__len__() - 1] else: break father_path = father_paths[father_paths.__len__() - 1] all_class_images = 0 # 读取每个类别 for class_dir in class_dirs: # 每个类别的信息 class_detail_list = {} test_sum = 0 trainer_sum = 0 # 把生产的数据列表都放在自己的总类别文件夹中 data_list_path = "/home/kesci/work/%s/" % father_path # 统计每个类别有多少张图片 class_sum = 0 # 获取类别路径 path = data_root_path + "/" + class_dir # 获取所有图片 img_paths = os.listdir(path) for img_path in img_paths: # 每张图片的路径 name_path = path + '/' + img_path # 如果不存在这个文件夹,就创建 isexist = os.path.exists(data_list_path) if not isexist: os.makedirs(data_list_path) # 每10张图片取一个做测试数据 trainer_sum += 1 with open(data_list_path + "trainer.list", 'a') as f: f.write(name_path + "\t%d" % class_label + "\n") class_sum += 1 all_class_images += 1 class_label += 1 # 说明的json文件的class_detail数据 class_detail_list['class_name'] = class_dir class_detail_list['class_label'] = class_label class_detail_list['class_test_images'] = test_sum class_detail_list['class_trainer_images'] = trainer_sum class_detail.append(class_detail_list) # 获取类别数量 all_class_sum = class_dirs.__len__() # 说明的json文件信息 readjson = {} readjson['all_class_name'] = father_path readjson['all_class_sum'] = all_class_sum readjson['all_class_images'] = all_class_images readjson['class_detail'] = class_detail jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': ')) with open(data_list_path + "readme.json",'w') as f: f.write(jsons)if __name__ == '__main__': createDataList = CreateDataList() createDataList.createTrainDataList('/mnt/datasets/WebFace/first_round/first_round_train/')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
# 把图像和label读取成readerfrom multiprocessing import cpu_countimport paddle.v2 as paddleclass MyReader: def __init__(self,imageSize): self.imageSize = imageSize def train_mapper(self,sample): ''' map image path to type needed by model input layer for the training set ''' img, label = sample img = paddle.image.load_image(img) img = paddle.image.simple_transform(img, int(self.imageSize * 1.2), self.imageSize, True) return img.flatten().astype('float32'), label def test_mapper(self,sample): ''' map image path to type needed by model input layer for the test set ''' img, label = sample img = paddle.image.load_image(img) img = paddle.image.simple_transform(img, int(self.imageSize * 1.2), self.imageSize, False) return img.flatten().astype('float32'), label def train_reader(self,train_list, buffered_size=1024): def reader(): with open(train_list, 'r') as f: lines = [line.strip() for line in f] for line in lines: img_path, lab = line.strip().split('\t') yield img_path, int(lab) return paddle.reader.xmap_readers(self.train_mapper, reader, cpu_count(), buffered_size) def test_reader(self,test_list, buffered_size=1024): def reader(): with open(test_list, 'r') as f: lines = [line.strip() for line in f] for line in lines: img_path, lab = line.strip().split('\t') yield img_path, int(lab) return paddle.reader.xmap_readers(self.test_mapper, reader, cpu_count(), buffered_size)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
# 定义网络import paddle.v2 as paddle# ***********************定义VGG卷积神经网络模型***************************************def vgg_bn_drop(datadim, type_size): # 获取输入数据模式 image = paddle.layer.data(name="image", type=paddle.data_type.dense_vector(datadim)) def conv_block(ipt, num_filter, groups, dropouts, num_channels=None): return paddle.networks.img_conv_group( input=ipt, num_channels=num_channels, pool_size=2, pool_stride=2, conv_num_filter=[num_filter] * groups, conv_filter_size=3, conv_act=paddle.activation.Relu(), conv_with_batchnorm=False, conv_batchnorm_drop_rate=dropouts, pool_type=paddle.pooling.Max()) conv1 = conv_block(image, 64, 2, [0.3, 0], 3) conv2 = conv_block(conv1, 128, 2, [0.4, 0]) conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0]) conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0]) conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0]) drop = paddle.layer.dropout(input=conv5, dropout_rate=0.5) # 这里修改成了Relu fc1 = paddle.layer.fc(input=drop, size=512, act=paddle.activation.Relu()) bn = paddle.layer.batch_norm(input=fc1, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) # 这里修改成了Relu fc2 = paddle.layer.fc(input=bn, size=512, act=paddle.activation.Relu()) # 通过Softmax获得分类器 out = paddle.layer.fc(input=fc2, size=type_size, act=paddle.activation.Softmax()) return fc2, out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
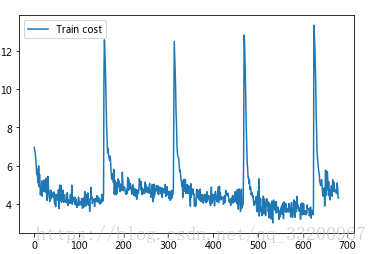
# 训练代码import osimport sysimport paddle.v2 as paddlefrom paddle.v2.plot import Ploterstep = 0class PaddleUtil: # **********************获取参数*************************************** def get_parameters(self, parameters_path=None, cost=None): if not parameters_path: # 使用cost创建parameters if not cost: raise NameError('请输入cost参数') else: # 根据损失函数创建参数 parameters = paddle.parameters.create(cost) print "cost" return parameters else: # 使用之前训练好的参数 try: # 使用训练好的参数 with open(parameters_path, 'r') as f: parameters = paddle.parameters.Parameters.from_tar(f) print "使用parameters" return parameters except Exception as e: raise NameError("你的参数文件错误,具体问题是:%s" % e) # ***********************获取训练器*************************************** # datadim 数据大小 def get_trainer(self, datadim, type_size, parameters_path, batch_size): # 获得图片对于的信息标签 label = paddle.layer.data(name="label", type=paddle.data_type.integer_value(type_size)) # 获取全连接层,也就是分类器 fea, out = vgg_bn_drop(datadim=datadim, type_size=type_size) # 获得损失函数 cost = paddle.layer.classification_cost(input=out, label=label) # 获得参数 if not parameters_path: parameters = self.get_parameters(cost=cost) else: parameters = self.get_parameters(parameters_path=parameters_path) ''' 定义优化方法 learning_rate 迭代的速度 momentum 跟前面动量优化的比例 regularzation 正则化,防止过拟合 ''' optimizer = paddle.optimizer.Momentum( momentum=0.9, regularization=paddle.optimizer.L2Regularization(rate=0.0005 * batch_size), learning_rate=0.00001 / batch_size, learning_rate_decay_a=0.1, learning_rate_decay_b=128000 * 35, learning_rate_schedule="discexp", ) ''' 创建训练器 cost 分类器 parameters 训练参数,可以通过创建,也可以使用之前训练好的参数 update_equation 优化方法 ''' trainer = paddle.trainer.SGD(cost=cost, parameters=parameters, update_equation=optimizer) return trainer # ***********************开始训练*************************************** def start_trainer(self, trainer, num_passes, save_parameters_name, trainer_reader, batch_size): # 获得数据 reader = paddle.batch(reader=paddle.reader.shuffle(reader=trainer_reader, buf_size=5000), batch_size=batch_size) # 保证保存模型的目录是存在的 father_path = save_parameters_name[:save_parameters_name.rfind("/")] if not os.path.exists(father_path): os.makedirs(father_path) # 指定每条数据和padd.layer.data的对应关系 feeding = {"image": 0, "label": 1} train_title = "Train cost" error_title = "Error" cost_ploter = Ploter(train_title, error_title) # 定义训练事件,画出折线图,该事件的图可以在notebook上显示,命令行不会正常输出 def event_handler_plot(event): global step if isinstance(event, paddle.event.EndIteration): if step % 1 == 0: cost_ploter.append(train_title, step, event.cost) # cost_ploter.append(error_title, step, event.metrics['classification_error_evaluator']) cost_ploter.plot() step += 1 if step % 100 == 0: # 保存训练好的参数 with open(save_parameters_name, 'w') as f: trainer.save_parameter_to_tar(f) ''' 开始训练 reader 训练数据 num_passes 训练的轮数 event_handler 训练的事件,比如在训练的时候要做一些什么事情 feeding 说明每条数据和padd.layer.data的对应关系 ''' trainer.train(reader=reader, num_passes=num_passes, event_handler=event_handler_plot, feeding=feeding)if __name__ == '__main__': paddle.init(use_gpu=False, trainer_count=4) # 类别总数 type_size = 1036 # 图片大小 imageSize = 224 # Batch Size batch_size = 32 # 总的分类名称 all_class_name = 'face' # 保存的model路径 parameters_path = "/home/kesci/work/model/model.tar" # 数据的大小 datadim = 3 * imageSize * imageSize # 训练的pass num_passes = 100 paddleUtil = PaddleUtil() # *******************************开始训练************************************** myReader = MyReader(imageSize=imageSize) # 获取训练器 trainer = paddleUtil.get_trainer(datadim=datadim, type_size=type_size, parameters_path=None, batch_size=batch_size) trainer_reader = myReader.train_reader(train_list="/home/kesci/work/first_round_train/trainer.list") paddleUtil.start_trainer(trainer=trainer, num_passes=num_passes, save_parameters_name=parameters_path, trainer_reader=trainer_reader, batch_size=batch_size)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
预测这个是预测代码,不要跟上的同时运行,因为不能重复初始化paddlepaddle。在提交结果代码中要写上自己的token。
# 定义网络import paddle.v2 as paddle# ***********************定义VGG卷积神经网络模型***************************************def vgg_bn_drop(datadim, type_size): # 获取输入数据模式 image = paddle.layer.data(name="image", type=paddle.data_type.dense_vector(datadim)) def conv_block(ipt, num_filter, groups, dropouts, num_channels=None): return paddle.networks.img_conv_group( input=ipt, num_channels=num_channels, pool_size=2, pool_stride=2, conv_num_filter=[num_filter] * groups, conv_filter_size=3, conv_act=paddle.activation.Relu(), conv_with_batchnorm=False, conv_batchnorm_drop_rate=dropouts, pool_type=paddle.pooling.Max()) conv1 = conv_block(image, 64, 2, [0.3, 0], 3) conv2 = conv_block(conv1, 128, 2, [0.4, 0]) conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0]) conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0]) conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0]) drop = paddle.layer.dropout(input=conv5, dropout_rate=0.5) # 这里修改成了Relu fc1 = paddle.layer.fc(input=drop, size=512, act=paddle.activation.Relu()) bn = paddle.layer.batch_norm(input=fc1, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) # 这里修改成了Relu fc2 = paddle.layer.fc(input=bn, size=512, act=paddle.activation.Relu()) # 通过Softmax获得分类器 out = paddle.layer.fc(input=fc2, size=type_size, act=paddle.activation.Softmax()) return fc2, out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
# 预测代码import numpy as npimport paddle.v2 as paddleimport osimport mathfrom sklearn import preprocessing# **********************获取参数***************************************def get_parameters(parameters_path): with open(parameters_path, 'r') as f: parameters = paddle.parameters.Parameters.from_tar(f) return parametersdef get_inference(parameters, fea): inferer = paddle.inference.Inference(output_layer=fea, parameters=parameters) return inferer# Python实现正态分布def gaussian(sigma, x, u): y = np.exp(-(x - u) ** 2 / (2 * sigma ** 2)) / (sigma * math.sqrt(2 * math.pi)) return y# ***********************使用训练好的参数进行预测***************************************def to_prediction(inferer, image_paths, imageSize): # 获得要预测的图片 test_data = [] for image_path in image_paths: test_data.append((paddle.image.load_and_transform(image_path, 224, imageSize, False) .flatten().astype('float32'),)) # 获得预测结果 probs = inferer.infer(input=test_data) prob1 = probs[0] prob2 = probs[1] # 欧几里得距离 dist = np.sqrt(np.sum(np.square(prob1 - prob2))) dist = 1/(1+dist) print dist return distif __name__ == '__main__': paddle.init(use_gpu=False, trainer_count=4) # 类别总数 type_size = 1036 # 图片大小 imageSize = 224 # 保存的model路径 parameters_path = "/home/kesci/work/model/model.tar" # 数据的大小 datadim = 3 * imageSize * imageSize # 获取预测器 parameters = get_parameters(parameters_path=parameters_path) fea, out = vgg_bn_drop(datadim=datadim, type_size=type_size) inferer = get_inference(parameters=parameters, fea=fea) # *******************************开始预测************************************** # 添加数据 images_list = [] with open("/mnt/datasets/WebFace/first_round/first_round_pairs_id.txt", "r") as f_images_lit: images_list = f_images_lit.readlines() del images_list[0] with open("/home/kesci/work/mysubmission.csv", "w") as f_result: f_result.write("submit_pairsID,prob\n") for i in range(len(images_list)): print("============================================================================") image_path = [] image_path1, image_path2 = images_list.replace("\n", "").split('_') image_path.append("/mnt/datasets/WebFace/first_round/first_round_test/%s.jpg" % image_path1) image_path.append("/mnt/datasets/WebFace/first_round/first_round_test/%s.jpg" % image_path2) result = to_prediction(inferer=inferer, image_paths=image_path, imageSize=imageSize) result_text = images_list.replace("\n", "") + "," + str(result) + "\n" f_result.write(result_text) print result_text- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
# 提交结果!./kesci_submit -token 你的token -file mysubmission.csv注意这个模型存在梯度爆炸的问题,笔者一直解决不了,如果读者解决这个问题了,希望告知一下笔者,谢谢。
作者: 不二晨 时间: 2018-8-9 17:37
奈斯
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) |
黑马程序员IT技术论坛 X3.2 |