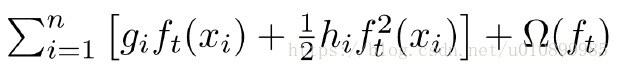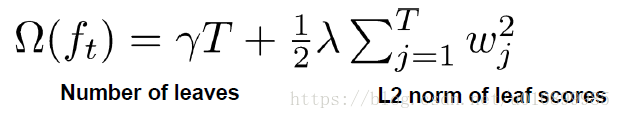GBDT和xgboost在工业界被越来越多的使用,尤其是在一些数据比赛中经常能看到它的身影,虽然在使用起来不难,但是要能完整的理解还是有一点麻烦的。本文在分享xgboost之前,先一步一步梳理GB,GBDT,xgboost,它们之间有非常紧密的联系,GBDT是以决策树(CART)为基学习器的GB算法,xgboost扩展和改进了GDBT,xgboost算法更快,准确率也相对高一些。
1.梯度增强(GB)机器学习中的学习算法的目标是为了优化或者说最小化损失功能,渐变助推的思想是迭代生成多个(M个)弱学习模型,然后将每个弱学习模型的预测结果相加,后面的模型FM + 1(x)的基于前面学习模型的FM(X)的效果生成的,关系如下:
GB算法的思想很简单,关键是怎么生成h(x)?
如果目标函数是回归问题的均方误差,很容易想到最理想的H(X)应该是能够完全拟合 ,这就是常说基于残差的学习。残差学习在回归问题中可以很好的使用,但是为了一般性(分类,排序问题),实际中往往是基于Loss Function在函数空间的负梯度学习,对于回归问题残差和负梯度也是相同的。中的f,不要理解为传统意义上的函数,而是一个函数向量 ,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。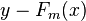


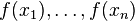
GB算法的步骤:
1.初始化模型为常数值:

2.迭代生成中号个基学习器
1.计算伪残差

2.基于 生成基学习器 

3.计算最优的

4.更新模型

GBDT(Gradient Boosted Decision Trees)在1999年由Jerome Friedman提出,将GBDT模型应用于CTR预估,最早见于
yahoo.GBDT是一个加性回归模型,通过boosting迭代的构造一组弱学习器,相对LR的优势如不需要做特征归一化,自动进行选择可解释性较低的模型,可以适应多种损失函数如Square Loss,Log Loss等。但作为非线性模型,其相对线性模型的缺点也是显然的:提升是个串行的过程,不能并化,计算复杂度较高,同时其不太适合高维稀疏特征,通常采用稠密的数值特征,如点击率预估中的COEC。
GB算法中最典型的基学习器是决策树,尤其是CART,正如名字的含义,GBDT是GB和DT的结合。要注意的是GDBT中使用的决策树是回归树,GBDT中的决策树是个弱模型,深度较小一般不会超过5,叶子节点的数量也不会超过10,对于生成的每棵决策树乘上比较小的缩减系数(学习率<0.1),有些GBDT的实现加入了随机抽样(子样0.5 <= f <= 0.8)提高模型的泛化能力。通过交叉验证的方法选择最优的参数。因此GBDT实际的核心问题变成怎么基于使用CART回归树生成?
作为对比,先说分类树,我们知道CART是二叉树,CART分类树在每次分枝时,是穷举每一个功能,每的一个阈值,根据基尼系数找到使不纯性降低最大的功能的以及其阀值,然后按照特征<=阈值,和特征>阈值分成的两个分枝,每个分支包含符合分支条件的样本。用同样方法继续分枝直到该分支下的所有样本都属于统一类别,或达到预设的终止条件,若最终叶子节点中的类别不唯一,则以多数人的类别作为该叶子节点的类别。
回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)得都会一个预测值,时分枝穷举每一个特征的每个阈值找最好的分割点,但衡量最好的标准不再是GINI系数,而是最小化:均方差。
3. xgboostxgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,不同于传统的GBDT方式,只利用了一阶的导数信息ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器.xgboost对损失func做了二阶的泰勒展开,并在目标函数之外加入正则项整体 求最优解,用以权衡目标函数的下降和模型复杂程度,避免过拟合。
模型如何学习:添加剂训练其中第一部分是训练误差,也就是大家相对比较熟悉的如平方误差,logistic loss等。而第二部分是每棵树的复杂度的和。这个在后面会继续讲到。因为现在我们的参数可以认为是在一个函数空间里面,我们不能采用传统的如SGD之类的算法来学习我们的模型,因此我们会采用一种叫做添加剂训练的方式也就是Boosting。每一次保留原来的模型不变,加入一个新的函数f到我们的模型中。
我们会采用如下的泰勒展开近似来定义一个近似的目标函数,方便我们进行这一步的计算。
其中,表示损失函数, 表示正则项,包括L1,L2,常数项。
GI为一阶导数,喜为二阶导数。
当我们把常数项移除之后,我们会发现如下一个比较统一的目标函数。这一个目标函数有一个非常明显的特点,它只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。
想一想当你被要求使用平方损失和logistic loss实现梯度树时,如何用代码分解模块?
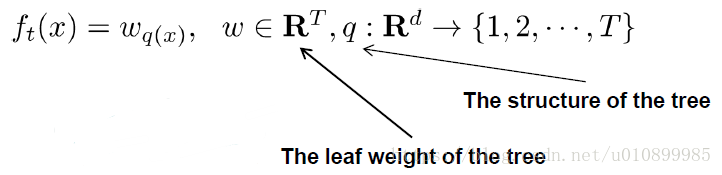
一个树的定义可以分成两个部分:结构部分和叶子权重部分。
假设q是结构映射函数把输入映射到叶子的索引号上面去,w表示叶子节点的权重。则树可以表示为:
定义树的正则项(复杂度):包含两个部分树的叶子节点的个数T和叶子节点的权重的平方(L2),即:
目标函数的OBJ
此时单棵决策树的学习过程如下:
(1)枚举所有可能的树结构q
(2)计算对应的分数(损失值)obj,obj越小越好
(3)找到最佳的树结构,为每个叶子节点计算权值w
然而,的可能树结构数量的英文无穷的,所以实际上我们不可能枚举所有可能的树结构。通常情况下,采用我们贪心策略来生成决策树的每个节点。
xgboost实现在做时还许多了优化:
- 从深度为0的树开始,每个对叶节点枚举所有的可用特征
- 针对每个特征,属于把该节点的训练样本根据该特征值升序个结果排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的最大收益(采用最佳分裂点时的收益)
- 选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,把该节点生长出左右两个新的叶节点,并为每个新节点关联对应的样本集
- 回到第1步,递归执行到满足特定条件为止
Xgboost分布式算法开始基本成熟后,分布式版本的变更主要是底层的AllReduce接口支持不同平台[mpi,yarn ....]的过程。
第一版支持MPI
Rabit开始兼容mpi的AllReduce,但是运行mpi的分布式程序需要读写hdfs,并分割数据。当时没有实现C ++读写hdfs功能,跑hdfs数据比较麻烦。
第二版支持Hadoop Streaming
通过Hadoop Streamingg把xgboost作为地图运行。在每个地图中进行allreduce的通信完xgboost每轮的迭代,减少只是负责输出模型。通过在一个地图中完成xgboost所有的迭代,避免了传统基于hadoop的机器学习程序每轮迭代间的资源重新分配,使得基于hadoop的xgboost的迭代速度能媲美基于mpi的xgboost,同时避免了,同时避免了mpi程序读写hdfs的麻烦。
第三版原生支持Yarn
Yarn为了能自由的掌控各个节点资源分配并且使文件均衡割到各个节点,直接把rabit作为纱的一个APP运行。在这一版里,实现了c ++读写hdfs的功能,解决了流版本中xgboost中对文件操作自由不高的问题。
目前xgboost支持 Python, R, Java, Scala, C++ and more.
Runs on single machine, Hadoop, Spark, Flink and DataFlow , https://xgboost.ai/
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |