Numpy,全称Numeric Python,是一个开源的Python科学计算库。
本文为基础知识(1),代码在jupyter中实现。
简介:
Numpy有一个强大的N维数组对象ndarray。该对象是一个快速而灵活的大数据集容器,该对象由两部分组成:
我们可以直接将array(数组)看作一种新的数据类型,就像list、tuple、dict一样,但数组中所有元素的类型必须是一致的,Python支持的数据类型有整型、浮点型以及复数型,但这些类型不足以满足科学计算的需求,因此NumPy中添加了许多其他的数据类型,如bool、inti、int64、float32、complex64等。同时,它也有许多其特有的属性和方法。
常用ndarray属性:当然,NumPy也有其不足之处,由于NumPy使用内存映射文件以达到最优的数据读写性能,而内存的大小限制了其对TB级大文件的处理;此外,NumPy数组的通用性不及Python提供的list容器。因此,在科学计算之外的领域,NumPy的优势也就不那么明显。
具体使用:
1 读取txt文档
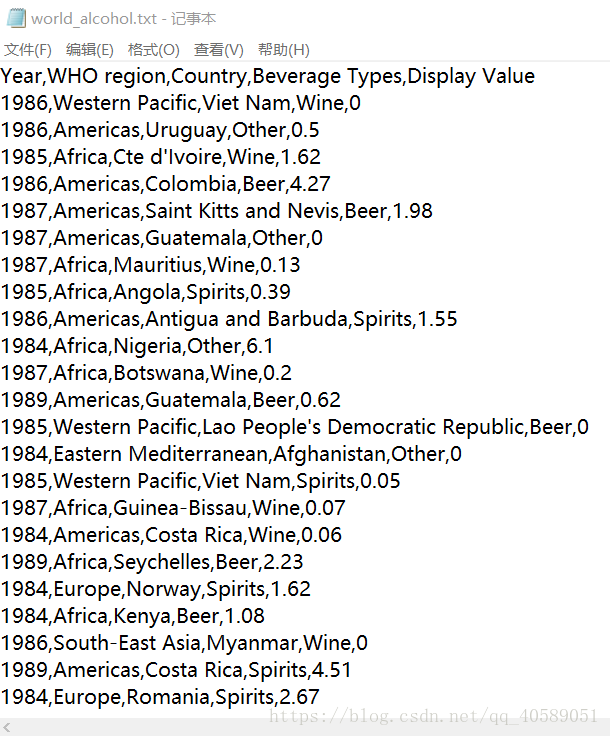
原始文档内容为:
#读取txt文档,分隔符为英文逗号,如果文档和代码放在同一路径下,可以不写文件路径。
world_alcohol = numpy.genfromtxt("world_alcohol.txt", delimiter=",")
print(type(world_alcohol))
读取结果的类型为:
<class 'numpy.ndarray'>2.numpy.array()的生成和运用。生成几维就用多少个[]。
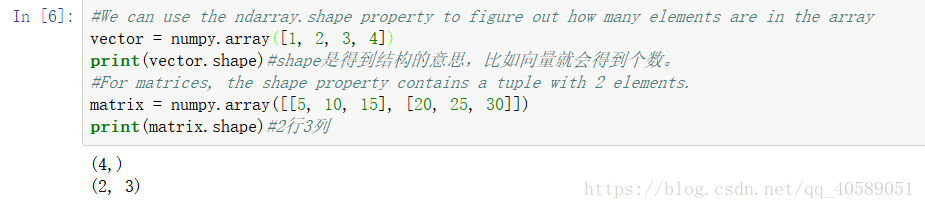
vecter.shape 得到ndarray的结构,如果是向量就会得到长度,二维就会得到几行几列。
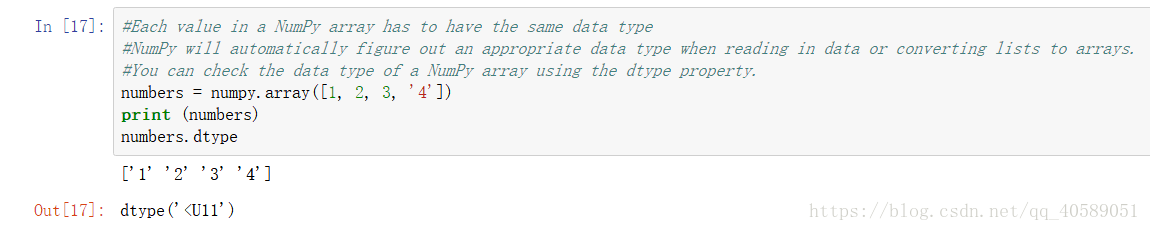
array中的类型要一致,否则会统一变成不一样的那个类型,比如如下代码。
二维矩阵操作。
3. np.array中的判断。
注意type()和dtype之间的区别。
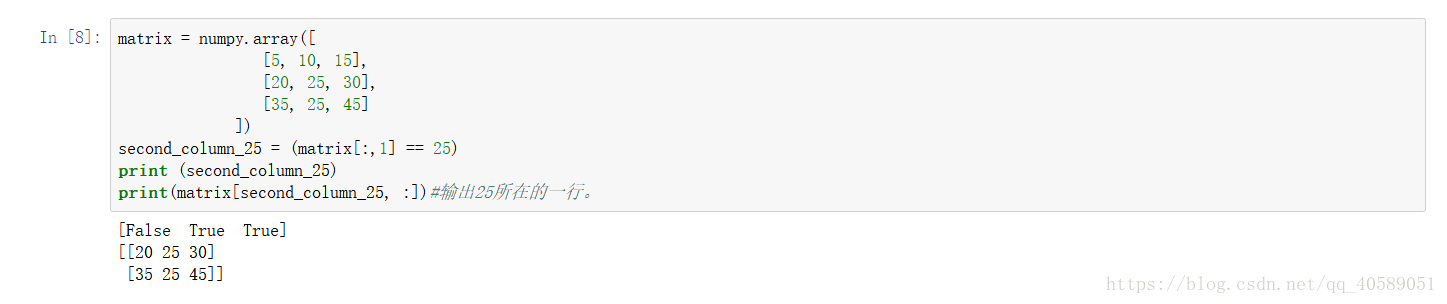
判断vector中是否有这个数字,返回bool类型的数组。
判断之后得到的array布尔值数组可以当做索引。
注意一维向量和二维矩阵之间的使用索引时的差别。
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |