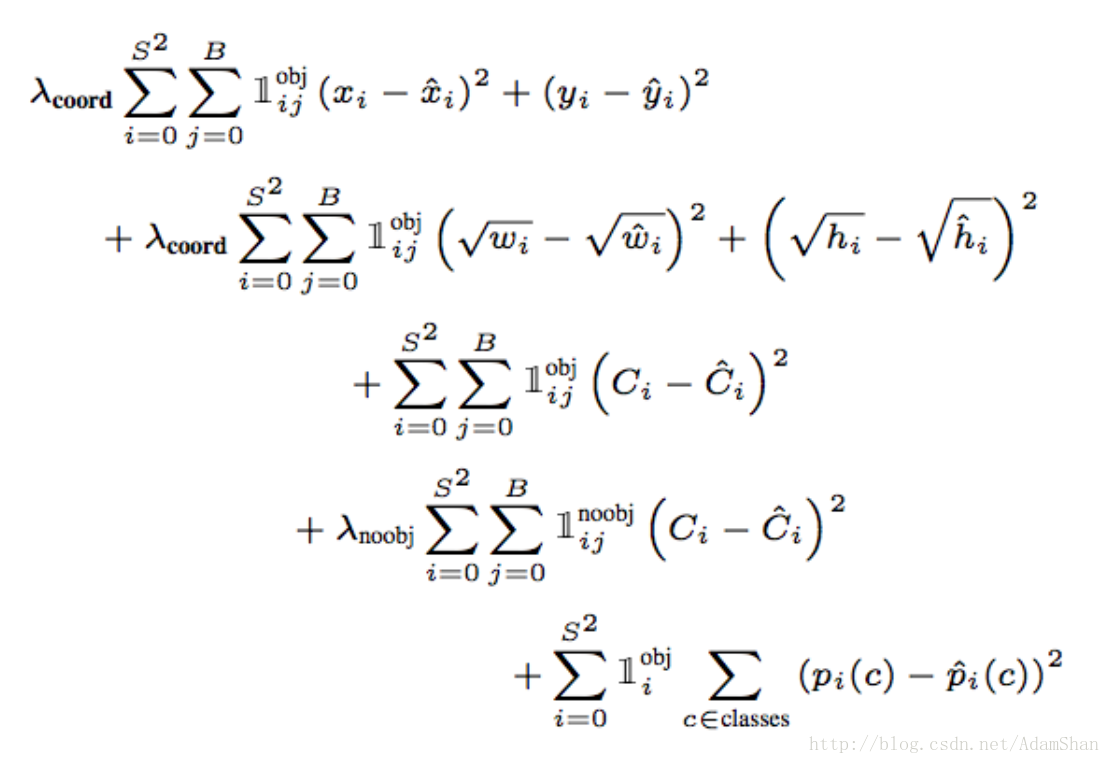
创作不易,转载请注明出处:http://blog.csdn.net/adamshan/article/details/79193775
什么是卷积,卷积的动机卷积运算卷积是一种特殊的线性运算,是对两个实值函数的一种数学运算,卷积运算通常用符号 <span class="MathJax" id="MathJax-Element-62-Frame" tabindex="0" data-mathml="∗" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">∗∗ 来表示,我们以Kalman滤波中的例子为例,来讨论一个一维离散形式的卷积:
假设我们的可回收飞船正在着陆,其传感器不断测量自身的高度信息,我们用 <span class="MathJax" id="MathJax-Element-63-Frame" tabindex="0" data-mathml="h(i)" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">h(i)h(i) 来表示 <span class="MathJax" id="MathJax-Element-64-Frame" tabindex="0" data-mathml="i" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ii 时刻的高度测量,这个测量是以一定的频率发生的(即每隔一个时间间隔测量一次,所以测量 <span class="MathJax" id="MathJax-Element-65-Frame" tabindex="0" data-mathml="h(i)是离散的" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">h(i)是离散的h(i)是离散的),受限于传感器,我们知道测量是不准确的,所以我们采用一种加权平均的方法来简单处理,具体来说,我们可以认为:越接近于时刻 <span class="MathJax" id="MathJax-Element-66-Frame" tabindex="0" data-mathml="i" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ii 的测量,越符合时刻 <span class="MathJax" id="MathJax-Element-67-Frame" tabindex="0" data-mathml="i" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ii 时的真实高度,即我们给测量 <span class="MathJax" id="MathJax-Element-68-Frame" tabindex="0" data-mathml="s(i)=wih(i)+wi−1h(i−1)+wi−2h(i−2)..." role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">s(i)=wih(i)+wi−1h(i−1)+wi−2h(i−2)...s(i)=wih(i)+wi−1h(i−1)+wi−2h(i−2)... 其中的权重 <span class="MathJax" id="MathJax-Element-69-Frame" tabindex="0" data-mathml="wi>wi−1>wi−2..." role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">wi>wi−1>wi−2...wi>wi−1>wi−2... 。这就是一个一维离散形式的卷积,由于这个例子中我们不可能得到“未来的测量”,所以只包含了一维离散卷积的一半,下面是一维离散卷积的完整公式:
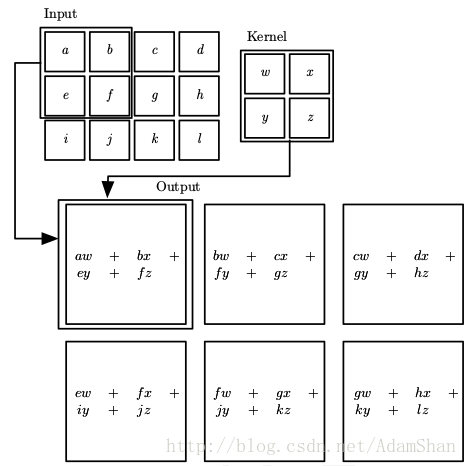
其中 <span class="MathJax" id="MathJax-Element-71-Frame" tabindex="0" data-mathml="i" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ii 表示我们计算的状态(时刻,位置),<span class="MathJax" id="MathJax-Element-72-Frame" tabindex="0" data-mathml="j" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">jj 表示到状态 <span class="MathJax" id="MathJax-Element-73-Frame" tabindex="0" data-mathml="i" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ii 的距离(可以是时间差,空间距离等等),这里的 <span class="MathJax" id="MathJax-Element-74-Frame" tabindex="0" data-mathml="h" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">hh 和 <span class="MathJax" id="MathJax-Element-75-Frame" tabindex="0" data-mathml="w" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ww 就分别表示两个实值函数。在卷积神经网络的术语中,第一个函数 <span class="MathJax" id="MathJax-Element-76-Frame" tabindex="0" data-mathml="h" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">hh 被称为输入,第二个函数 <span class="MathJax" id="MathJax-Element-77-Frame" tabindex="0" data-mathml="w" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ww 被称为 核函数(kernal function) , 输出 <span class="MathJax" id="MathJax-Element-78-Frame" tabindex="0" data-mathml="s" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ss 被称为 特征映射(feature map),很显然,在实际的例子中,<span class="MathJax" id="MathJax-Element-79-Frame" tabindex="0" data-mathml="j" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">jj (即我们考量的区间)一般不会是负无穷大到正无穷大,它通常是个很小的范围。在深度学习的应用中,输入通常是高维度的数组(比如说图像),而核函数也是由算法(如随机梯度下降)产生的高维参数数组。如果输入二维图像 <span class="MathJax" id="MathJax-Element-80-Frame" tabindex="0" data-mathml="I" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">II ,那么相应的我们也需要使用二维的核 <span class="MathJax" id="MathJax-Element-81-Frame" tabindex="0" data-mathml="K" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">KK,则这个二维卷积可以写为:
其中,<span class="MathJax" id="MathJax-Element-127-Frame" tabindex="0" data-mathml="(m,n)" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">(m,n)(m,n) 是计算的像素位置, <span class="MathJax" id="MathJax-Element-128-Frame" tabindex="0" data-mathml="(i,j)" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">(i,j)(i,j) 是考量的范围。我们用更加直观的形式来表示的话,二维卷积如下所示:
那么在回答了什么是卷积以后,我们看看为什么使用卷积这种线性运算。首先我们看看卷积神经网络的定义:
卷积神经网络是指在网络中至少使用了一层卷积运算来代替一般的矩阵乘法运算的神经网络。
我们知道,全连接层中的输入边实际上是乘权重再累加,即本质上是一个矩阵乘法,那么卷积层实际上就是用卷积这种运算替代了原来全连接层中的矩阵乘法,卷积的出发点是通过下述三种思想来改进机器学习系统:
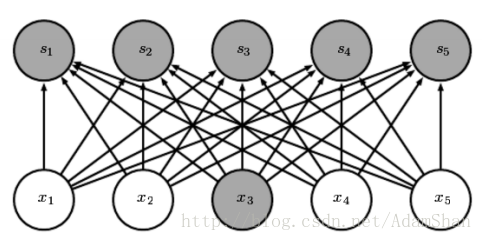
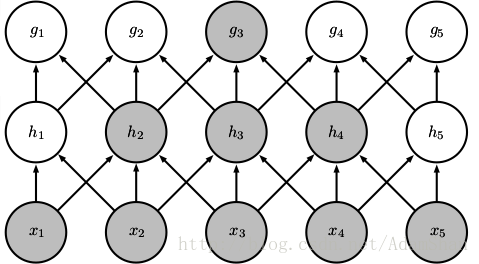
对于普通的全连接网络,层与层之间的节点是全连接的:
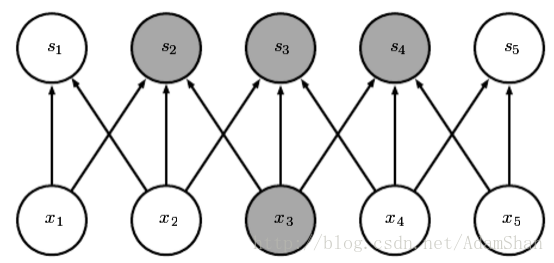
但是对卷积网络而言,下一层的节点只与其卷积核作用到的节点相关:
(图片出处: Goodfellow et al. Deep learning. 2016.)
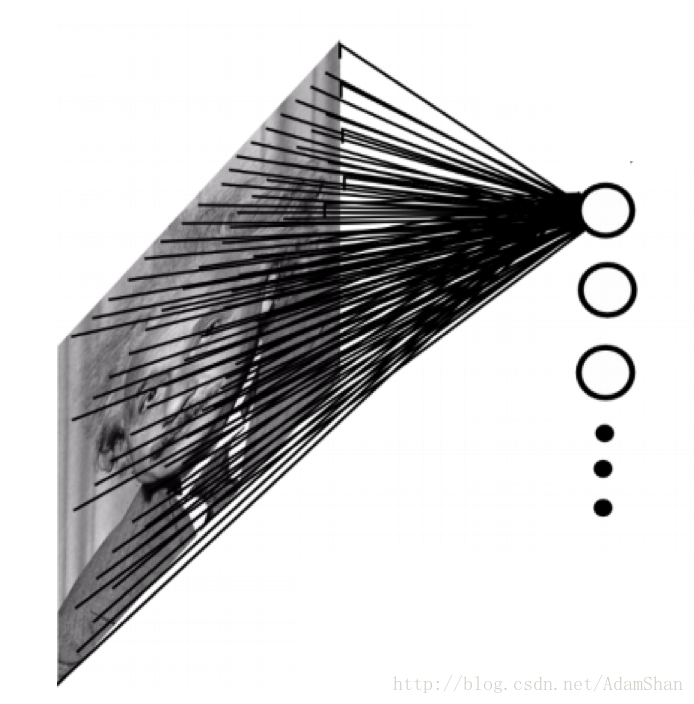
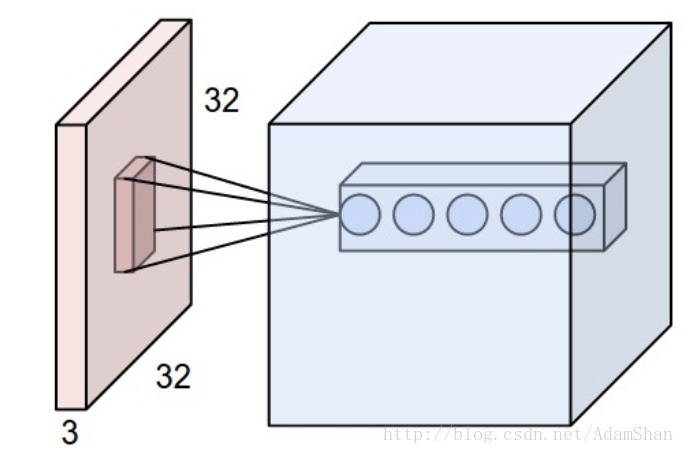
使用稀疏连接的一个直观的好处就是网络的参数更少了,我们以一副 <span class="MathJax" id="MathJax-Element-149-Frame" tabindex="0" data-mathml="200×200" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">200×200200×200 的灰度图为例,当将它输入到全连接的神经网络中时,如下:
假设这个网络的的第一个隐含层有4万个神经元(对于输入样本为40000维的情况来说,40000个隐含层节点是合适的),那么这个网络光这一层就有接近20亿个参数。这样的模型训练的计算量是非常大的,且需要很大的存储空间。
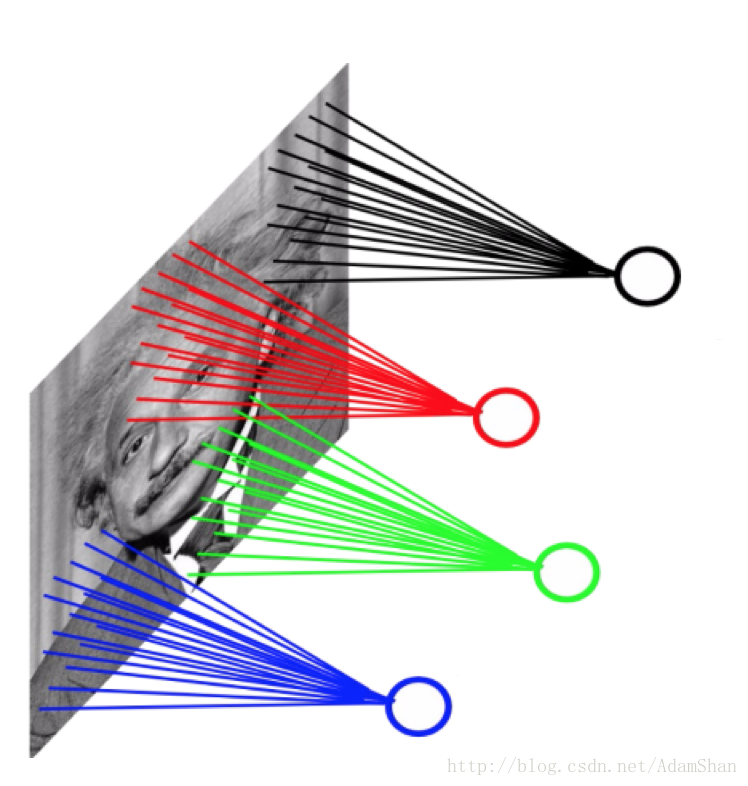
对于卷积网络而言,情况如下:
这里我们仍然使用40000个隐含层神经元,我们的卷积核(也被称为滤波(Filter))的大小为 <span class="MathJax" id="MathJax-Element-150-Frame" tabindex="0" data-mathml="10×10" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">10×1010×10 ,这样的一层卷积的参数量只有约4000000个,参数数量远远小于全连接的网络。
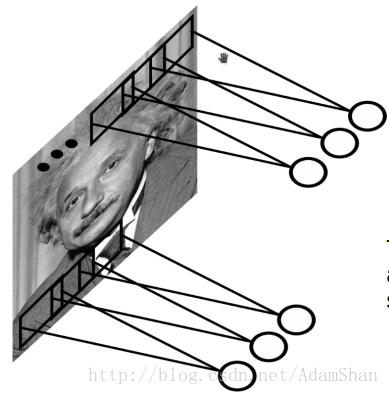
读者可能会有疑问?卷积的输出只与输入的局部产生关联,如果某种规律并不是建立在局部特征之上,而是和整个输入都有关联,那么通过卷积建立起来的表示是不是就不完整呢?并非如此。现代的卷积网络往往需要叠加多个卷积层,卷积网络虽然在直接连接上是稀疏的,但是在更深的层中的单元可以间接的连接到全部的或者大部分的输入图像,如下图所示:
参数共享提示:在卷积网络的相关文献中,存在术语:神经元(neuron),核(kernal),滤波(filter),它们都指同一个事物——核函数,在本文中,我们统一称为卷积核。
使用卷积核实际上就是卷积网络的参数,卷积核在输入图像上滑动窗口,这也就意味着输入的图像的像素点共享这一套参数,如下图所示:
卷积网络中的参数共享使我们只需要学习一个参数集合,而不需要对每一个像素都学习一个单独的参数集合,它使得模型所需的存储空间大幅度降低。
等变表示由于整个输入图片共享一组参数,那么模型对于图像中的某些特征平移具有 等变性 。那么,何谓等变呢?
如果函数 <span class="MathJax" id="MathJax-Element-87-Frame" tabindex="0" data-mathml="f(x)" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">f(x)f(x) 和函数 <span class="MathJax" id="MathJax-Element-88-Frame" tabindex="0" data-mathml="g(x)" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">g(x)g(x) 满足:
那么我们称函数 <span class="MathJax" id="MathJax-Element-90-Frame" tabindex="0" data-mathml="f" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ff 对变换 <span class="MathJax" id="MathJax-Element-91-Frame" tabindex="0" data-mathml="g" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">gg 具有等变性。同理,平移就是函数 <span class="MathJax" id="MathJax-Element-92-Frame" tabindex="0" data-mathml="g" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">gg ,那么如果我们平移输入的对象,那么输出中建立的表示也会平移相同的量,这一性质在检测输入中的某些共有结构(比如说边缘)是非常有用的,尤其在卷积神经网络的前几层(靠近输入的层)。
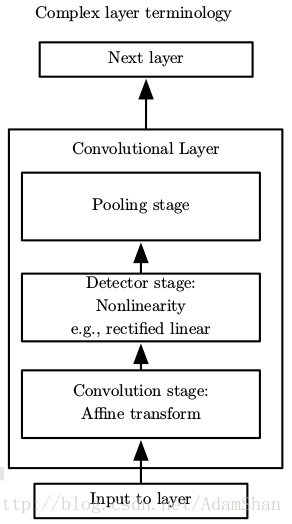
卷积神经网路下图是一个典型的卷积神经网络层(我们简称卷积层),传统的卷积层包含如下三个结构:
这里的激活函数起着与全连接网络一样的作用,<span class="MathJax" id="MathJax-Element-152-Frame" tabindex="0" data-mathml="ReLU" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ReLUReLU 是最常用的激活函数,下面我们来详细讨论一下池化。
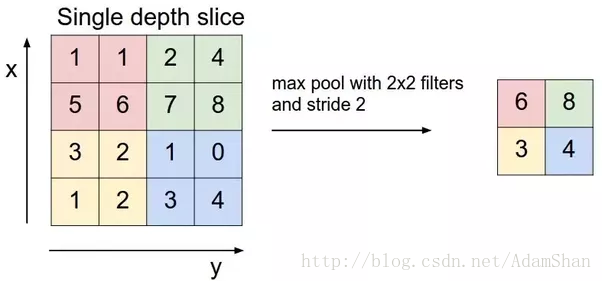
池化池化通常也被称为池化函数,池化函数的定义就是:一种使用相邻位置的总体统计特征来替换该位置的值,池化的理念有点向时序问题中的滑动窗口平均。下图表示一种池化方法——最大池化(maxpooling):
上图表示一个2×2的最大池化,其步幅(Stride)为2,我们可以理解为,使用一个 <span class="MathJax" id="MathJax-Element-157-Frame" tabindex="0" data-mathml="2×2" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">2×22×2 的窗口,以2为步长在输入图像上滑动窗口,计算窗口之内输入元素的最大值并输出。我们不难发现,经过这样一个池化函数以后,输入的尺寸被“压缩”了,同时,池化并没有引入额外的参数,即池化能够降低输入的尺寸,也就意味着我们在后面的卷积层中需要的参数更少,因此,在使用池化以后,整个神经网络的参数数量会进一步降低。下面是池化的输入输出的尺寸计算公式:
假设输入的尺寸为:<span class="MathJax" id="MathJax-Element-158-Frame" tabindex="0" data-mathml="w×h×d" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">w×h×dw×h×d,步幅为 <span class="MathJax" id="MathJax-Element-159-Frame" tabindex="0" data-mathml="s" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ss ,窗口的大小为 <span class="MathJax" id="MathJax-Element-160-Frame" tabindex="0" data-mathml="f×f" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">f×ff×f ,则输出的宽,高和深度分别为:
常用的池化函数主要有最大池化(Max Pooling)和平均池化(Average Pooling),分别是输出相邻的矩阵区域的最大值和平均值,不论是哪种池化,都对于输入的图像中的目标的少量平移具有不变性,即输入中的目标对象发生少量的平移,池化函数的输出不会发生改变。当我们对于卷积的输出进行池化时,由于卷积学习的是分离的特征(比如底层的卷积学习到的是各种边缘特征),特征可能存在一些变换(平移,旋转等等),添加池化函数,能够进一步学习到应该对哪些变换具有不变性。
卷积的一些细节我们前面大致了解了什么是卷积,在卷积神经网络中,卷积计算还有一些细节问题要考虑。
填充和输入输出尺寸首先,就是输入输出的尺寸换算。和前面的池化一样,我们假设输入的尺寸为 <span class="MathJax" id="MathJax-Element-101-Frame" tabindex="0" data-mathml="w×h×d" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">w×h×dw×h×d,卷积的步幅为 <span class="MathJax" id="MathJax-Element-102-Frame" tabindex="0" data-mathml="s" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ss ,卷积核的大小为 <span class="MathJax" id="MathJax-Element-103-Frame" tabindex="0" data-mathml="f×f" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">f×ff×f ,卷积网络中往往还有一个处理方法,叫做填充(padding),如果我们不想让我们的卷积核越过图像的边界去滑动的话,我们称之为 有效填充(valid padding) ,令 <span class="MathJax" id="MathJax-Element-104-Frame" tabindex="0" data-mathml="p" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">pp 为填充的像素数,则使用有效填充来处理边界时 <span class="MathJax" id="MathJax-Element-105-Frame" tabindex="0" data-mathml="p=0" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">p=0p=0,然而,在卷积网络的前几层中,我们要保存尽可能多的原始输入信息,以便我们可以提取这些低阶特征。我们想要应用同样的卷积层,但我们想将输出量保持与输入相同的宽高,为了做到这一点,我们使用一定数量的0填充在边界的周围,使得卷积的输出和输入有着相同的宽高,我们称之为 相同填充(same padding)。输出的宽,高和深度的计算为:
其中, <span class="MathJax" id="MathJax-Element-109-Frame" tabindex="0" data-mathml="k" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">kk 表示卷积核的深度。
卷积核的深度通常来说,我们回使用多个卷积核,如下图所示:
不同的核学习不同的特征,有些核可能学习的是一些颜色特征,有些核可能学习的是一些边缘,形状特征,下图是同一层中已经训练好的卷积神经网络的核可视化效果(Krizhevsky et al.)
卷积核的数量我们成为卷积核的深度。
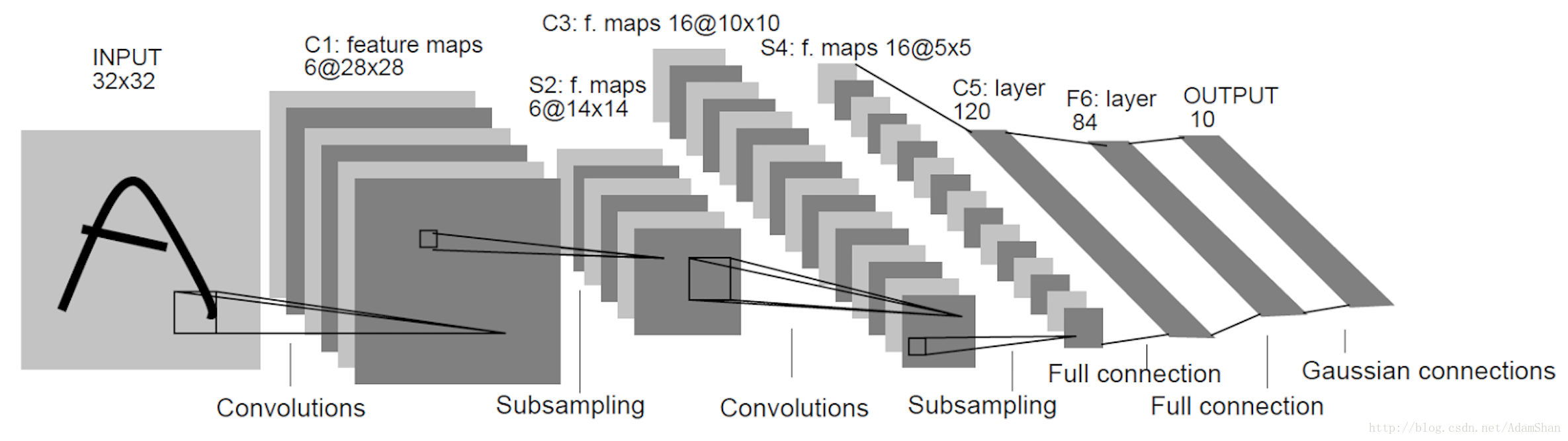
LeNet下图是LeNet是LeCun等人在1998年提出的用于解决手写字识别的卷积网络,其整体结构如下:
我们从LeNet出发来了解卷积网络的设计模式。如图,卷积网络通常使用金字塔形结构,即随着层数的增加,输出的深度不断增加,同时,我们使用诸如池化,valid padding和大步幅来缩小输出的宽高尺寸。同时,卷积核的尺寸选择已有一定的技巧,通常来说,我们往往在靠近输入的卷积层中使用较大的卷积核以缩小输出的尺寸(如 <span class="MathJax" id="MathJax-Element-163-Frame" tabindex="0" data-mathml="7×7" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">7×77×7 ),而在后面的卷积层中使用小卷积核以充分建立特征表示(如 <span class="MathJax" id="MathJax-Element-164-Frame" tabindex="0" data-mathml="3×3" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">3×33×3 )。
卷积网络的末端和前馈神经网络类似,我们将最后一个卷积层的输出展成向量,输入到一个多层感知机中,对于分类问题,仍然是使用交叉熵作为损失函数,使用随机梯度下降等算法训练整个神经网络的参数。
基于YOLO的实时车辆检测卷积神经网络的可视化例子:http://scs.ryerson.ca/~aharley/vis/conv/
YOLO(you only look once) 是一种目标检测模型。在深度学习出现之前,传统的目标检测方法的步骤主要是:
其主要问题有两方面:一方面滑窗选择策略没有针对性、时间复杂度高,窗口冗余;另一方面手工设计的特征鲁棒性较差,分类器不可靠。
自深度学习出现之后,目标检测取得了巨大的突破,最瞩目的两个方向有:1 以RCNN为代表的基于Region Proposal的深度学习目标检测算法(RCNN,SPP-NET,Fast-RCNN,Faster-RCNN等);2 以YOLO为代表的基于回归方法的深度学习目标检测算法(YOLO,SSD等)。我们介绍基于回归方法的深度学习目标检测方法——YOLO,并且使用YOLO的tiny版本实现一个实时的车辆检测DEMO。
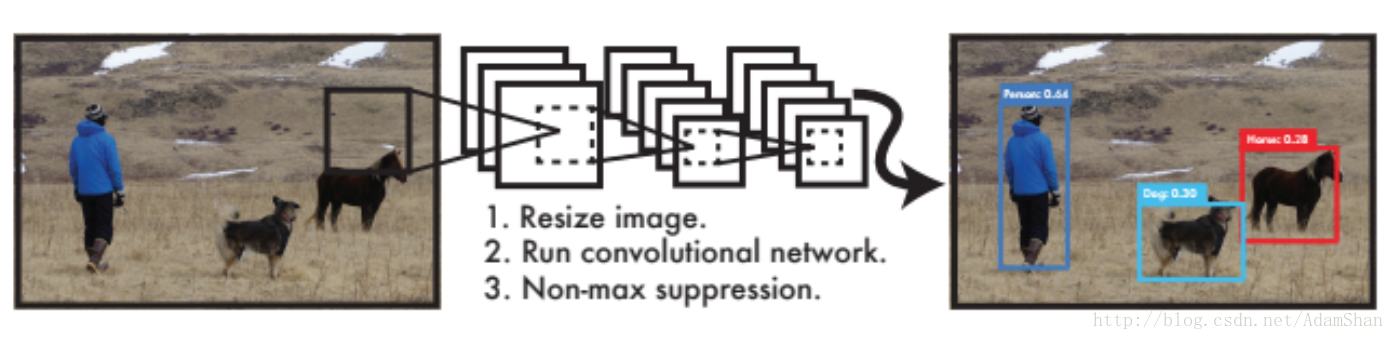
YOLOYOLO将目标检测看作是一个回归问题,训练好的网络的工作流程非常简单,如下图所示:
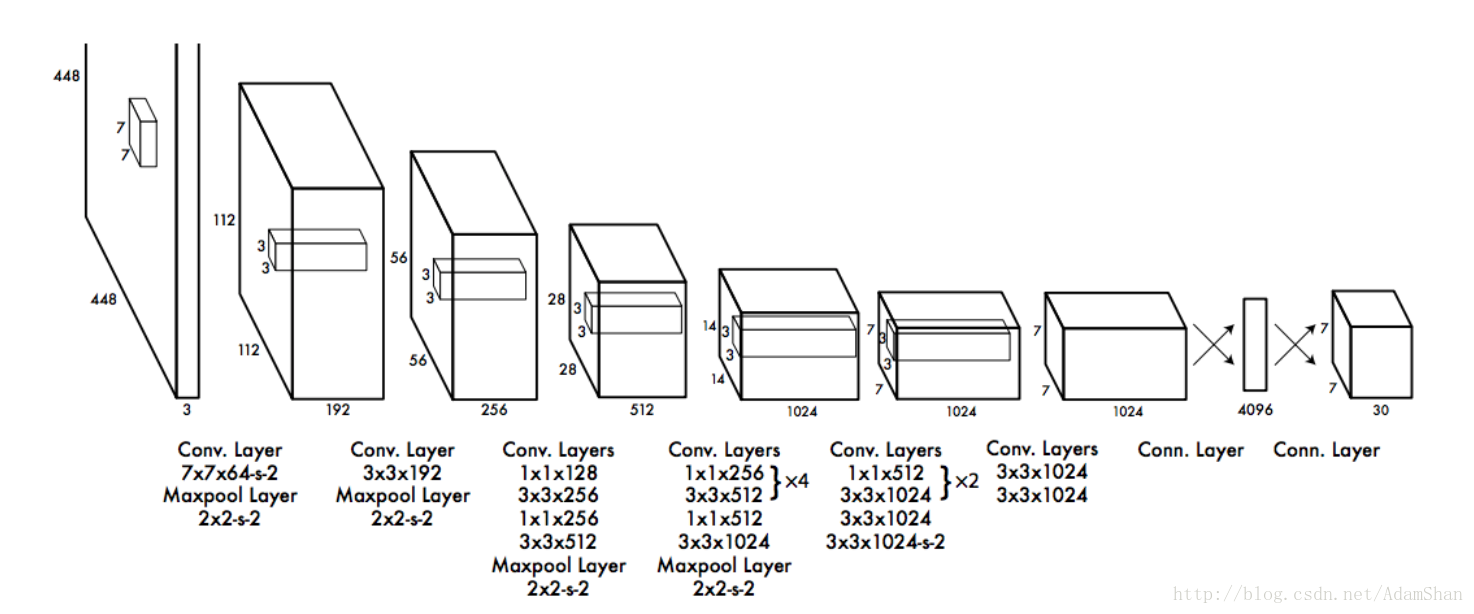
如图,作为End-To-End网络,输入原始图像,输出即为目标的位置和其所属类别及相应的置信概率。不同于传统的滑动窗口检测算法,在训练和应用阶段,YOLO都使用的是整张图片作为输入。YOLO的具体网络结构如下:
整个网络包含了24个卷积层以及2个全连接层,以下是YOLO的整个流程:
预训练分类网络接着就是将训练的分类网络用于检测,在预训练好的20个卷积层的后面再添加4个卷积层和2个全链接层(即结构图中的后4个卷积层和最后两个全连接层),在这里,网络的输入变成了 <span class="MathJax" id="MathJax-Element-173-Frame" tabindex="0" data-mathml="448×448" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">448×448448×448 , 输出是一个 <span class="MathJax" id="MathJax-Element-174-Frame" tabindex="0" data-mathml="7×7×32" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">7×7×327×7×32 的张量。
输入到检测网络的图片首先会被resize成 <span class="MathJax" id="MathJax-Element-175-Frame" tabindex="0" data-mathml="448×448" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">448×448448×448 ,然后被被分割成 <span class="MathJax" id="MathJax-Element-176-Frame" tabindex="0" data-mathml="7×7" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">7×77×7 的网格。
网络的输出 <span class="MathJax" id="MathJax-Element-177-Frame" tabindex="0" data-mathml="7×7×30" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">7×7×307×7×30 负责这7*7个网格的回归预测。我们来看看这每个网格的30个输出构成:
每个网格都要预测2个bounding box,bounding box即我们用来圈出目标的矩形(也就是目标所在的一个矩形区域),一个bounding box包含如下信息:
每个网格都要预测两个bounding box,即10个输出,此外,还有20个输出代表目标的类别,YOLO论文在训练时一共检测20类物体,所以一共有20个类别的输出,我们记做 <span class="MathJax" id="MathJax-Element-180-Frame" tabindex="0" data-mathml="C" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">CC ,合集每个网格的预测输出有30个数值。
损失函数要很好地回归出这30个数值,损失函数的设计就必须在bounding box坐标,宽高,置信,类别之间达到一个很好的平衡。YOLO使用如下函数作为检测网络的损失函数:
在测试阶段,每个网格预测的类别信息和bounding box预测的confidence相乘,就得到每个bounding box的class-specific confidence score。那么对整个图像的每个网格都做这种操作,则可以得到 <span class="MathJax" id="MathJax-Element-122-Frame" tabindex="0" data-mathml="7×7×2=98" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">7×7×2=987×7×2=98 个bounding box,这些bounding box既包含坐标等信息也包含类别信息。
得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
基于YOLO的车辆检测代码NMS(Non-maximum suppression):非最大抑制,它首先基于物体检测分数产生检测框,分数最高的检测框M被选中,其他与被选中检测框有明显重叠的检测框被抑制。在本例中,使用YOLO网络预测出一系列带分数的预选框,当选中最大分数的检测框M,它被从集合B中移出并放入最终检测结果集合D。于此同时,集合B中任何与检测框M的重叠部分大于重叠阈值Nt的检测框也将随之移除。
由于车辆检测对实时性要求高,我们使用一种YOLO的简化版本:Fast YOLO,该模型使用简单的9层卷积替代了原来的24层卷积,它牺牲了一定的精度,处理速度更快,从YOLO的45fps提升到155fps。满足实时目标检测的需求。
使用Keras实现fast YOLO网络结构:
model = Sequential()model.add(Convolution2D(16, 3, 3,input_shape=(3,448,448),border_mode='same',subsample=(1,1)))model.add(LeakyReLU(alpha=0.1))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Convolution2D(32,3,3 ,border_mode='same'))model.add(LeakyReLU(alpha=0.1))model.add(MaxPooling2D(pool_size=(2, 2),border_mode='valid'))model.add(Convolution2D(64,3,3 ,border_mode='same'))model.add(LeakyReLU(alpha=0.1))model.add(MaxPooling2D(pool_size=(2, 2),border_mode='valid'))model.add(Convolution2D(128,3,3 ,border_mode='same'))model.add(LeakyReLU(alpha=0.1))model.add(MaxPooling2D(pool_size=(2, 2),border_mode='valid'))model.add(Convolution2D(256,3,3 ,border_mode='same'))model.add(LeakyReLU(alpha=0.1))model.add(MaxPooling2D(pool_size=(2, 2),border_mode='valid'))model.add(Convolution2D(512,3,3 ,border_mode='same'))model.add(LeakyReLU(alpha=0.1))model.add(MaxPooling2D(pool_size=(2, 2),border_mode='valid'))model.add(Convolution2D(1024,3,3 ,border_mode='same'))model.add(LeakyReLU(alpha=0.1))model.add(Convolution2D(1024,3,3 ,border_mode='same'))model.add(LeakyReLU(alpha=0.1))model.add(Convolution2D(1024,3,3 ,border_mode='same'))model.add(LeakyReLU(alpha=0.1))model.add(Flatten())model.add(Dense(256))model.add(Dense(4096))model.add(LeakyReLU(alpha=0.1))model.add(Dense(1470))训练YOLO网络是一个漫长的过程,这里我们直接使用已经训练好的模型,将模型参数加载到keras模型中,参数下载地址:https://drive.google.com/file/d/0B1tW_VtY7onibmdQWE1zVERxcjQ/view?usp=sharing
该下载链接需要科学上网,文末有训练好的fast YOLO的百度网盘下载链接。
加载参数文件到我们的网络中:
def load_weights(model, yolo_weight_file): tiny_data = np.fromfile(yolo_weight_file, np.float32)[4:] index = 0 for layer in model.layers: weights = layer.get_weights() if len(weights) > 0: filter_shape, bias_shape = [w.shape for w in weights] if len(filter_shape) > 2: # For convolutional layers filter_shape_i = filter_shape[::-1] bias_weight = tiny_data[index:index + np.prod(bias_shape)].reshape(bias_shape) index += np.prod(bias_shape) filter_weight = tiny_data[index:index + np.prod(filter_shape_i)].reshape(filter_shape_i) filter_weight = np.transpose(filter_weight, (2, 3, 1, 0)) index += np.prod(filter_shape) layer.set_weights([filter_weight, bias_weight]) else: # For regular hidden layers bias_weight = tiny_data[index:index + np.prod(bias_shape)].reshape(bias_shape) index += np.prod(bias_shape) filter_weight = tiny_data[index:index + np.prod(filter_shape)].reshape(filter_shape) index += np.prod(filter_shape) layer.set_weights([filter_weight, bias_weight])从YOLO网络的输出中提取出车辆的检测结果:
def yolo_net_out_to_car_boxes(net_out, threshold=0.2, sqrt=1.8, C=20, B=2, S=7): class_num = 6 boxes = [] SS = S * S # number of grid cells prob_size = SS * C # class probabilities conf_size = SS * B # confidences for each grid cell probs = net_out[0: prob_size] confs = net_out[prob_size: (prob_size + conf_size)] cords = net_out[(prob_size + conf_size):] probs = probs.reshape([SS, C]) confs = confs.reshape([SS, B]) cords = cords.reshape([SS, B, 4]) for grid in range(SS): for b in range(B): bx = Box() bx.c = confs[grid, b] bx.x = (cords[grid, b, 0] + grid % S) / S bx.y = (cords[grid, b, 1] + grid // S) / S bx.w = cords[grid, b, 2] ** sqrt bx.h = cords[grid, b, 3] ** sqrt p = probs[grid, :] * bx.c if p[class_num] >= threshold: bx.prob = p[class_num] boxes.append(bx) # combine boxes that are overlap boxes.sort(key=lambda b: b.prob, reverse=True) for i in range(len(boxes)): boxi = boxes if boxi.prob == 0: continue for j in range(i + 1, len(boxes)): boxj = boxes[j] if box_iou(boxi, boxj) >= .4: boxes[j].prob = 0. boxes = [b for b in boxes if b.prob > 0.] return boxes在测试图片上的检测结果:
在测试视频上的效果:
YOLO 论文: https://pjreddie.com/media/files/papers/yolo.pdf
训练好的Fast YOLO百度网盘下载链接:https://pan.baidu.com/s/1o9twnPo完整代码下载链接:http://download.csdn.net/download/adamshan/10229339
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |