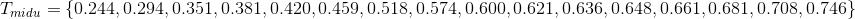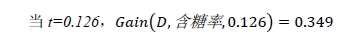黑马程序员技术交流社区
标题:
【上海校区】决策树(decision tree)(三)——连续值处理
[打印本页]
作者:
不二晨
时间:
2018-9-9 10:50
标题:
【上海校区】决策树(decision tree)(三)——连续值处理
前面两篇博客分别介绍了如何构造决策树(根据信息增益,信息增益率,基尼指数等)和如何对决策树进行剪枝(预剪枝和后剪枝),但是前面两篇博客主要都是基于离散变量的,然而我们现实的机器学习任务中会遇到连续属性,这篇博客主要介绍决策树如何处理连续值。
| 连续值处理
因为连续属性的可取值数目不再有限,因此不能像前面处理离散属性枚举离散属性取值来对结点进行划分。因此需要连续属性离散化,常用的离散化策略是二分法,这个技术也是C4.5中采用的策略。下面来具体介绍下,如何采用二分法对连续属性离散化:
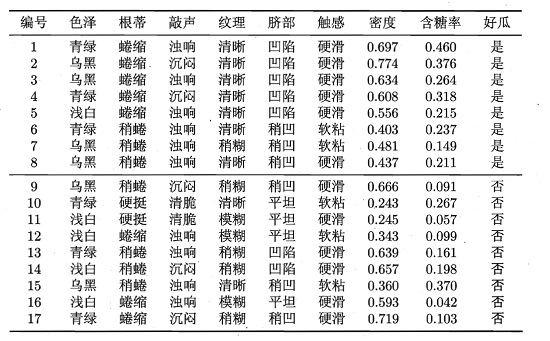
下面举个具体的例子,来看看到底是怎样划分的。给定数据集如下(数据集来自周志华《机器学习》,我已经把数据集放到github上了,地址为:
西瓜数据集3.0
):
对于数据集中的属性“密度”,决策树开始学习时,根节点包含的17个训练样本在该属性上取值均不同。我们先把“密度”这些值从小到大排序:
根据上面计算
的公式,可得:
下面开始计算
t
取不同值时的信息增益:
对属性“含糖率”,同样的计算,能够计算出:
再由第一篇博客中
决策树(一)
计算得到的各属性的信息增益值:
比较能够知道纹理的信息增益值最大,因此,“纹理”被选作根节点划分属性,下面只要重复上述过程递归的进行,就能构造出一颗决策树:
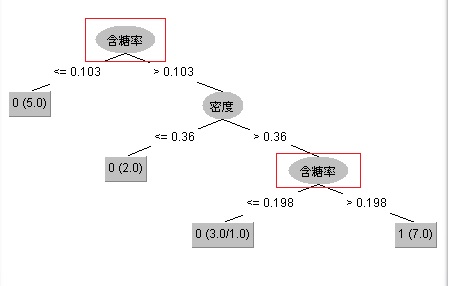
**有一点需要注意的是:与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性。**
如下图所示的一颗决策树,“含糖率”这个属性在根节点用了一次,后代结点也用了一次,只是两次划分点取值不同。
以上就是决策树如何处理连续值的内容,关于如何处理缺失值,因为我会写的比较详细,所以如果和连续值放在一起,会显得篇幅过长,因此放在下一篇博客中单独介绍。
作者:
不二晨
时间:
2018-9-13 16:26
很不错,受教了
作者:
魔都黑马少年梦
时间:
2018-11-1 16:48
欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/)
黑马程序员IT技术论坛 X3.2


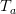 的公式,可得:
的公式,可得: