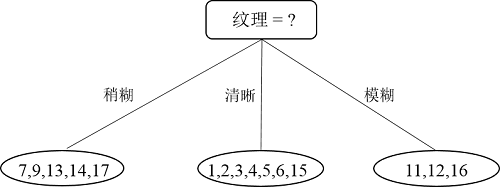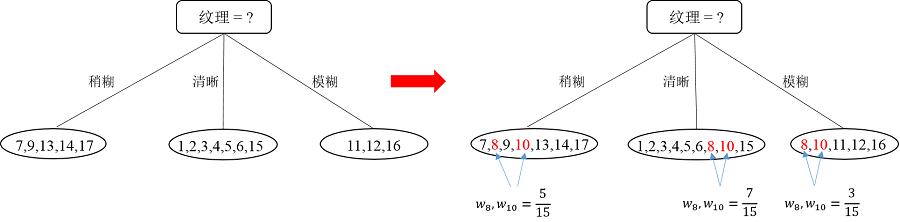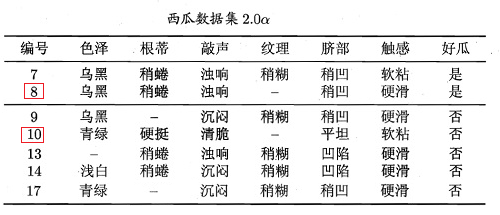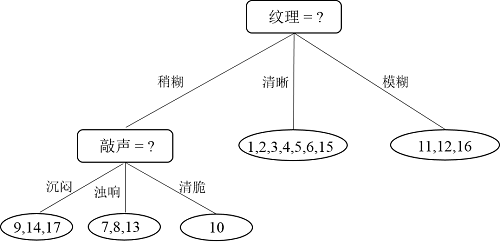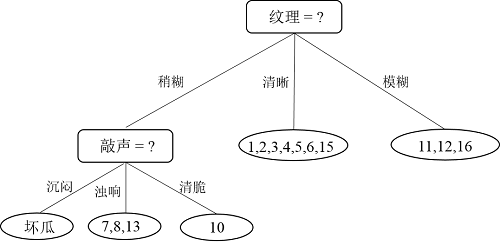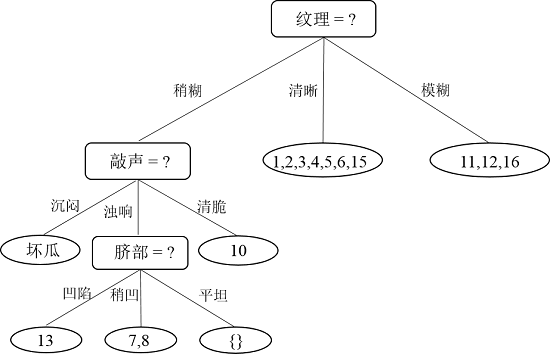
接下来,继续,对于结点{13},因为就一个样本了,直接把该结点标记为叶结点,类别为“坏瓜”;递归到结点{7,8},因为样本类别相同,所以也标记为叶结点,类别为“好瓜”;递归到结点“脐部=平坦”,因为这个结点不包含任何样本为空集,因此,把该结点标记为叶结点,类别设置为父节点中多数类的类别,即为“好瓜”。因此“纹理=稍糊”这颗子树构造完毕,如下图所示:
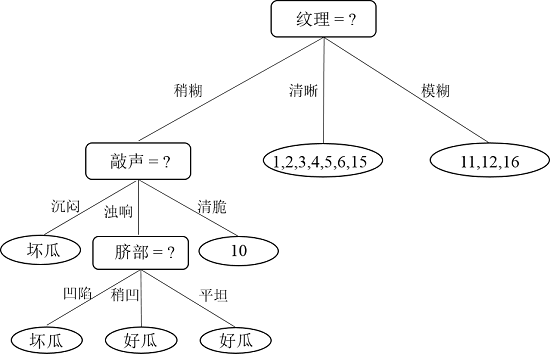
接下来,只需递归的重复上述过程即可,即能训练出一颗完整的决策树,最终的决策树如下图所示(该图片来自西瓜书):
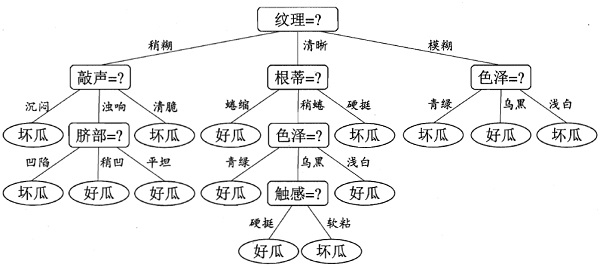
关于决策树中的缺失值处理就介绍到,欢迎大家留言交流。