在许多自然语言处理任务中,许多单词表达是由他们的tf-idf分数决定的。即使这些分数告诉我们一个单词在一个文本中的相对重要性,但是他们并没有告诉我们单词的语义。Word2vec是一类神经网络模型——在给定无标签的语料库的情况下,为语料库中的单词产生一个能表达语义的向量。这些向量通常是有用的:
- 通过词向量来计算两个单词的语义相似性
- 对某些监督型NLP任务如文本分类,语义分析构造特征
接下来我将描述Word2vec其中一个模型,叫做skip-gram模型
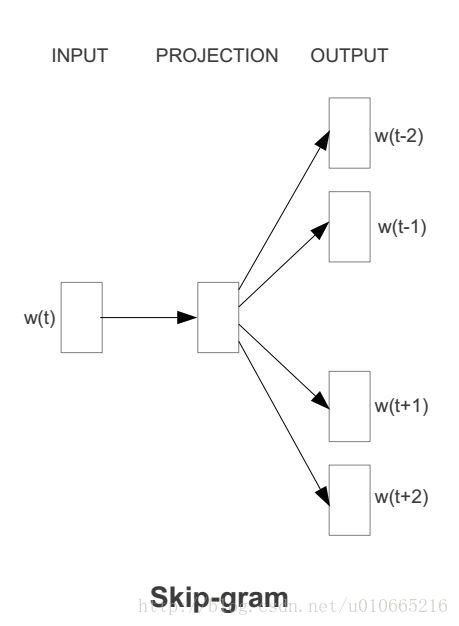
skip-gram模型在我详细介绍skip-gram模型前,我们先来了解下训练数据的格式。skip-gram模型的输入是一个单词<span class="MathJax" id="MathJax-Element-1-Frame" tabindex="0" data-mathml="wI" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">wIwI,它的输出是<span class="MathJax" id="MathJax-Element-2-Frame" tabindex="0" data-mathml="wI" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">wIwI的上下文<span class="MathJax" id="MathJax-Element-3-Frame" tabindex="0" data-mathml="wO,1,...,wO,C" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">wO,1,...,wO,CwO,1,...,wO,C,上下文的窗口大小为<span class="MathJax" id="MathJax-Element-4-Frame" tabindex="0" data-mathml="C" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">CC。举个例子,这里有个句子“I drive my car to the store”。我们如果把”car”作为训练输入数据,单词组{“I”, “drive”, “my”, “to”, “the”, “store”}就是输出。所有这些单词,我们会进行one-hot编码。skip-gram模型图如下所示:
接下来我们来看下skip-gram神经网络模型,skip-gram的神经网络模型是从前馈神经网络模型改进而来,说白了就是在前馈神经网络模型的基础上,通过一些技巧使得模型更有效。我们先上图,看一波skip-gram的神经网络模型:

在上图中,输入向量<span class="MathJax" id="MathJax-Element-5-Frame" tabindex="0" data-mathml="x" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">xx代表某个单词的one-hot编码,对应的输出向量{<span class="MathJax" id="MathJax-Element-6-Frame" tabindex="0" data-mathml="y1" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">y1y1,…,<span class="MathJax" id="MathJax-Element-7-Frame" tabindex="0" data-mathml="yC" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">yCyC}。输入层与隐藏层之间的权重矩阵<span class="MathJax" id="MathJax-Element-8-Frame" tabindex="0" data-mathml="W" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">WW的第<span class="MathJax" id="MathJax-Element-9-Frame" tabindex="0" data-mathml="i" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ii行代表词汇表中第<span class="MathJax" id="MathJax-Element-10-Frame" tabindex="0" data-mathml="i" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">ii个单词的权重。接下来重点来了:这个权重矩阵<span class="MathJax" id="MathJax-Element-11-Frame" tabindex="0" data-mathml="W" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">WW就是我们需要学习的目标(同<span class="MathJax" id="MathJax-Element-12-Frame" tabindex="0" data-mathml="W′" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">W′W′),因为这个权重矩阵包含了词汇表中所有单词的权重信息。上述模型中,每个输出单词向量也有个<span class="MathJax" id="MathJax-Element-13-Frame" tabindex="0" data-mathml="N×V" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">N×VN×V维的输出向量<span class="MathJax" id="MathJax-Element-14-Frame" tabindex="0" data-mathml="W′" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">W′W′。最后模型还有<span class="MathJax" id="MathJax-Element-15-Frame" tabindex="0" data-mathml="N" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">NN个结点的隐藏层,我们可以发现隐藏层节点<span class="MathJax" id="MathJax-Element-16-Frame" tabindex="0" data-mathml="hi" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">hihi的输入就是输入层输入的加权求和。因此由于输入向量<span class="MathJax" id="MathJax-Element-17-Frame" tabindex="0" data-mathml="x" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">xx是one-hot编码,那么只有向量中的非零元素才能对隐藏层产生输入。因此对于输入向量<span class="MathJax" id="MathJax-Element-18-Frame" tabindex="0" data-mathml="x" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">xx其中<span class="MathJax" id="MathJax-Element-19-Frame" tabindex="0" data-mathml="xk=1" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">xk=1xk=1并且<span class="MathJax" id="MathJax-Element-20-Frame" tabindex="0" data-mathml="xk′=0,k≠k′" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">xk′=0,k≠k′xk′=0,k≠k′。所以隐藏层的输出只与权重矩阵第<span class="MathJax" id="MathJax-Element-21-Frame" tabindex="0" data-mathml="k" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; text-align: left; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; word-break: break-all; position: relative;">kk行相关,从数学上证明如下:
前面我讲解了skip-gram模型的输入向量及输出的概率表达,以及我们学习的目标。接下来我们详细讲解下学习权重的过程。第一步就是定义损失函数,这个损失函数就是输出单词组的条件概率,一般都是取对数,如下所示:
从上面的更新规则,我们可以发现,每次更新都需要对整个词汇表求和,因此对于很大的语料库来说,这个计算复杂度是很高的。于是在实际应用中,Google的Mikolov等人提出了分层softmax及负采样可以使得计算复杂度降低很多。

| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |