黑马程序员技术交流社区
标题:
【上海校区】机器学习实战(用Scikit-learn和TensorFlow进行机器...
[打印本页]
作者:
不二晨
时间:
2018-10-10 09:05
标题:
【上海校区】机器学习实战(用Scikit-learn和TensorFlow进行机器...
本帖最后由 不二晨 于 2018-10-10 11:23 编辑
一、简介
Scikit-learn集成了很多机器学习需要使用的函数,学习Scikit-learn能简洁、快速写出机器学习程序。本文章主要是对真实数据进行实战,手把手带你走一遍使用机器学习对真实数据进行处理的全过程。并且通过代码更加深入的了解机器学习模型,学习如何处理数据,如何选择模型,如何选择和调整模型参数。
二、配置必要的环境
1、推荐安装Anaconda(集成Python和很多有用的Package)
2、编辑器:Spyder 或 Pycharm 或 Jupyter Notebook
三、开始实战(处理CSV表格数据)
1、下载数据
数据集为房屋信息housing,代码运行后,会下载一个tgz文件,然后用tarfile解压,解压后目录中会有一个housing.scv文件(可以自行用excel打开看看),下载代码为:
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
2、读入数据
通过panda库读取csv文件。
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
3、观察数据
载入数据以后,首先就是要观察数据是否成功导入,是否存在缺失值,是否存在异常值,数据的特征呈现何种分布等。
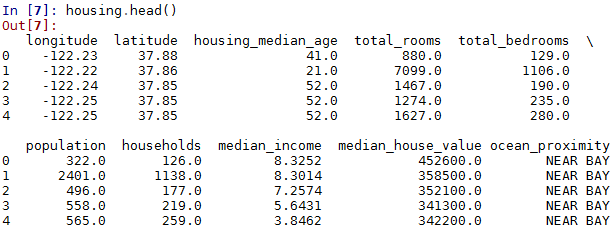
head()输出前5个数据和表头
head()可以查看数据是否成功导入,并可以查看数据包含哪些特征以及特征的形式大概是怎么样的。
housing.head()
输出结果
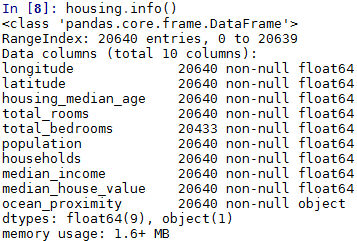
info()输出每个特征的元素总个数以及类型信息等
info()可以查看每个特征的元素总个数,因此可以查看某个特征是否存在缺失值。还可以查看数据的类型以及内存占用情况。
housing.info()
输出结果
可以看到total_bedrooms特征总个数为20433,而不是20640,所以存在缺失值。除了ocean_proximity为object类型(一般为一些文字label)以外,其余特征都为浮点型(float64)
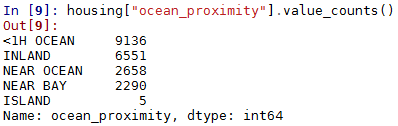
value_counts()统计特征中每个元素的总个数
value_counts()一般用在统计有有限个元素的特征(如标签label,地区等)
housing["ocean_proximity"].value_counts()
输出结果
可以看到ocean_proximity特征元素分为5类,以及每一类的总个数。
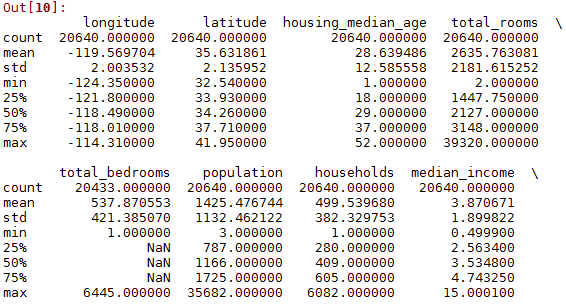
describe()可以看实数特征的统计信息
describe()可以看实数特征的最大值、最小值、平均值、方差、总个数、25%,50%,75%小值。
housing.describe()
输出结果
其中count为总个数,mean为平均值,std为标准差,min为最小值,max为最大值,25%,50%,75%为第25%,50%,75%的最小值。
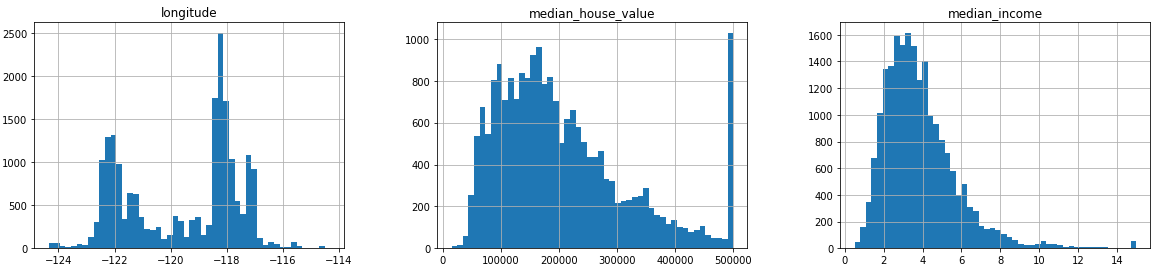
hist()输出实数域的直方图
同过hist()生成直方图,能够查看实数特征元素的分布情况。
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
输出结果
可以看到第一个图的分布为两个峰;第二、三个图近似为长尾分布(Long-tailed distributions)。
需要注意:hist()函数需要配合matplotlib包使用
4、分开训练和测试集
为了最终验证模型是否具有推广泛化能力,需要分开训练集于测试集,假设将数据集分为80%训练,20%测试。下面为一种普遍的分开数据集的代码:
import numpy as np
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
train_set, test_set = split_train_test(housing, 0.2)
print(len(train_set), "train +", len(test_set), "test")
这虽然能正确的分开训练、测试集,但是如果重新运行程序,训练和测试集会不一样。假设在原来模型的基础上继续训练,则不能保证测试集没有被模型训练过,因此不能验证模型效果。下面有两种方案:
方案一:使用在shuffle之前(即permutation),调用np.random.seed(42),则每次运行shuffle的结果一样(即训练、测试集一样)。但是如果新增加了一些数据集,则这个方案将不可用。
方案二:为了解决方案一的问题,采用每个样本的识别码(可以是ID,可以是行号)来决定是否放入测试集,例如计算识别码的hash值,取hash值得最后一个字节(0~255),如果该值小于一个数(20% * 256)则放入测试集。这样,这20%的数据不会包含训练过的样本。具体代码如下:
def test_set_check(identifier, test_ratio, hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash))
return data.loc[~in_test_set], data.loc[in_test_set]
housing_with_id = housing.reset_index() # adds an `index` column
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
如果用行号作识别码,需要保证新的数据放在之前的数据以后,而且没有行被删除。如果没有办法做到以上两条准则,则可以应该使用更加稳定的特征作为识别码,例如一个地区的经纬度(longitude 和 latitude)。
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
简洁、方便的Scikit-Learn 也提供了相关的分开训练和测试集的函数。
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
参数和之前几乎相同,random_state为0或没有时为每次随机的情况,42时为seed的情况。
需要注意:如果没有找到model_selection,请将sklearn更新到最新版本(pip install -U sklearn)
由于上面的情况都只是考虑纯随机采样,如果样本很大,则能表现良好,如果样本比较少,则会有采样偏差的风险。比如要对1000个人做问卷调查,社会人口男女比例为51.3%和48.7%,则采样人数按照这个比例,则应该为513和487,这就是分层采样。如果纯随机采样(即上述按行号,识别码的随机采样),则有12%的可能测试集中女性少于49%或男性多于54%。这样的话就会产生采样偏差。因此sklearn提供了另一个函数StratifiedShuffleSplit(分层随机采样)
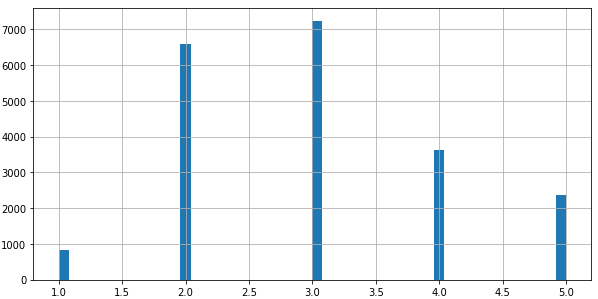
继续从真实数据来看,假设专家告诉你median_income 是用于预测median housing price一个很重要的特征,则你想把median_income作为划分的准则来观察不同的median_income对median housing price的影响。但是可以看到median_income是连续实数值。所以需要把median_income变为类别属性。
根据之前显示的图标表,除以1.5界分为5类,除了以后大于5的归为5,下面图片可以上述说过的hist()函数画出来看看,对比一下原来的median_income的分布,看是否相差较大,如果较大,则界需要调整。
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
接下来就可以根据上面分号层的”income_cat”使用StratifiedShuffleSplit函数作分层采样,其中n_splits为分为几组样本(如果需要交叉验证,则n_splits可以取大于1,生成多组样本),其他参数和之前相似。
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
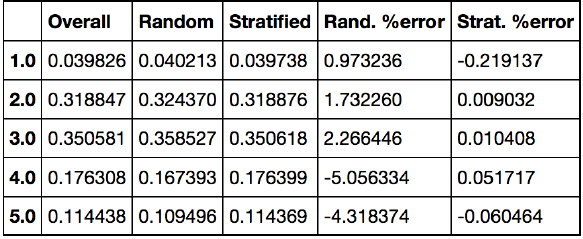
最后我们来比较一下分层采样和随机采样的结果比例情况
从表格中可以看到纯随机采样产生的采样偏差还是比较大的。
由于income_cat特征只是我们用于划分的特征,对训练没有任何作用,所以最后需要将加入的income_cat删除
for set in (strat_train_set, strat_test_set):
set.drop(["income_cat"], axis=1, inplace=True)
【转载】 原文:
https://blog.csdn.net/fjl_csdn/a ... 856?utm_source=copy
作者:
不二晨
时间:
2018-10-10 11:39
奈斯
作者:
魔都黑马少年梦
时间:
2018-11-1 16:31
欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/)
黑马程序员IT技术论坛 X3.2