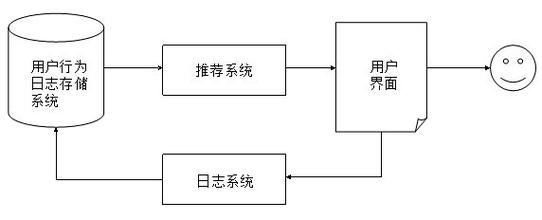
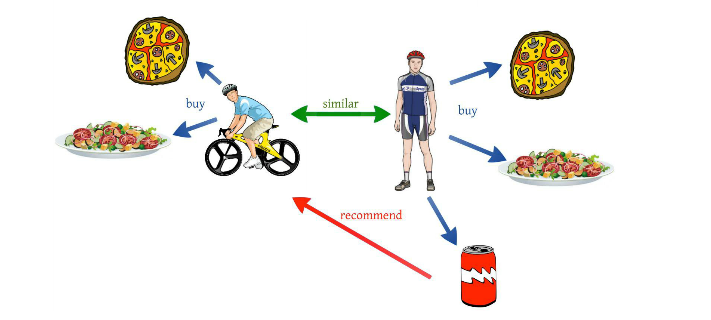
第二代协同过滤技术是基于物品的协同过滤算法,基于物品的协同过滤算法与基于用户的协同过滤算法基本类似。他使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。这听起来比较拗口,简单的说就是几件商品同时被人购买了,就可以认为这几件商品是相似的,可能这几件商品的商品名称风马牛不相及,产品属性有天壤之别,但通过模型算出来之后就是认为他们是相似的。什么?你觉得不可思议,无法理解。是的,就是这么神奇!
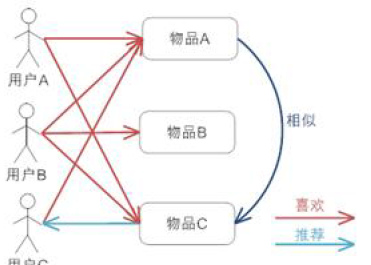
举个例子:假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
下图是基于物品的协同过滤算法,该图片来自百度图片。