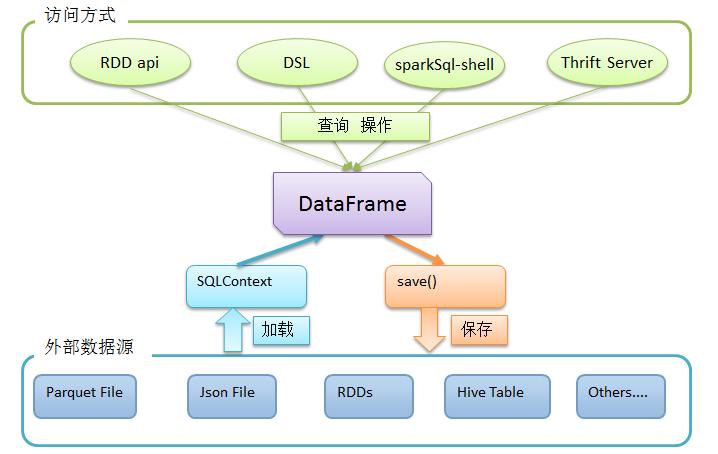
如果在spark-shell中执行sql查询,使用sqlContext对象调用sql()方法
scala> sqlContext.sql("select remote_addr from dw_weblog.t_ods_detail group by remote_addr").collect.foreach(println)
如果是在spark-sql中执行sql查询,则可以直接输入sql语句
scala> show databases
scala> use dw_weblog
scala> select remote_addr from dw_weblog.t_ods_detail group by remote_addr
5、在IDEA中编写代码使用hive-sql
如下所示:
val hiveContext = new HiveContext(sc)
import hiveContext.implicits._
import hiveContext.sql
//指定库
sql("use dw_weblog")
//执行标准sql语句
sql("create table sparksql as select remote_addr,count(*) from t_ods_detail group by remote_addr")
……