知乎上经常会有很多令人忍俊不禁的神回复,初看之下拍案叫绝,细思之下更是回味无穷。本文就来介绍下如何爬取知乎的神回复,揭晓其背后的原理。

知乎神回复都有些什么特点呢?我们先来观察一下,
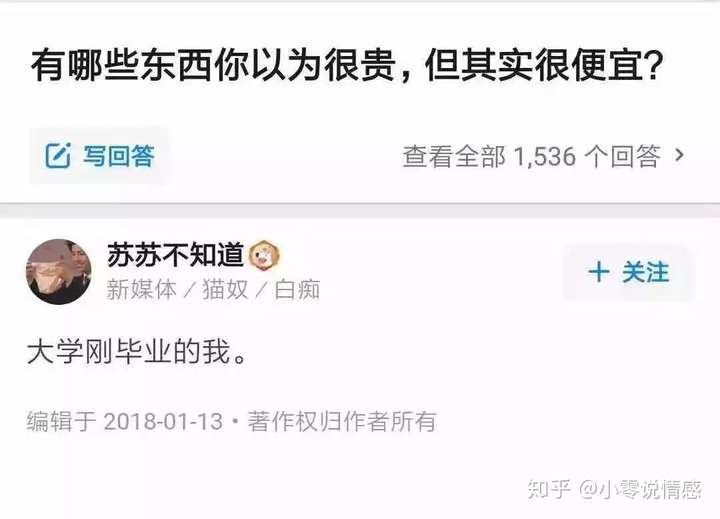
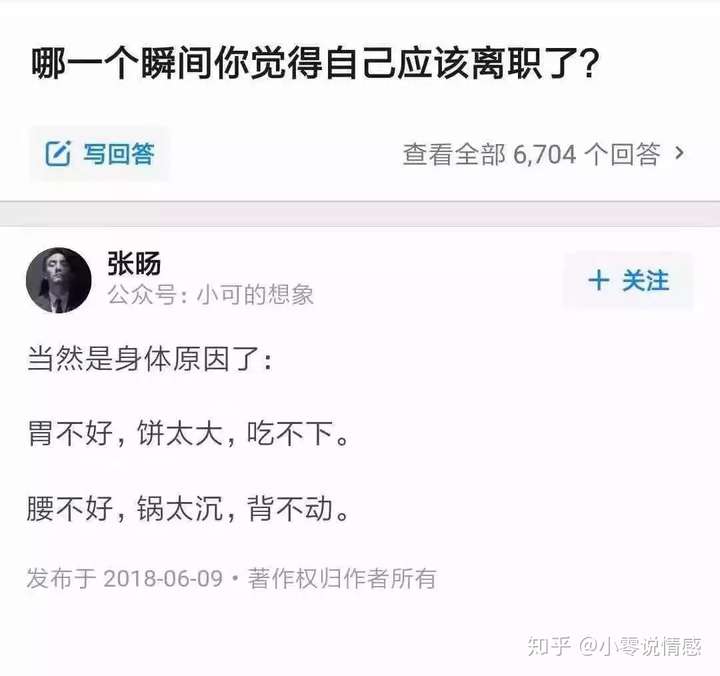
大家看出什么规律了么?短小精辟有没有?赞同很多有没有?所以爬取知乎神回复我们只要爬取那些赞同多又字数少的回答就可以。
简单的两个步骤就能实现,第一步爬取知乎回答,第二部筛选回答。是不是很 easy?
爬取知乎回答
第一步我们爬取知乎上的回答。知乎上的回答太多了,一下子爬取所有的回答会很费时,我们可以选定几个话题,爬取这几个话题里的内容。
下面的函数用于爬取某一个指定话题的内容:
def get_answers_by_page(topic_id, page_no): offset = page_no * 10 url = <topic_url> # topic_url是这个话题对应的url headers = { "User-Agent": "www.idiancai.com/Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36", } r = requests.get(url, verify=False, headers=headers) content = r.content.decode("utf-8") data = json.loads(content) is_end = data["paging"]["is_end"] items = data["data"] client = pymongo.MongoClient() db = client["zhihu"] if len(items) > 0: db.answers.insert_many(items) db.saved_topics.insert({"topic_id": topic_id, "page_no": page_no}) return is_endget_answers_by_page 函数有两个参数,第一个参数是话题的 id,第二个参数表示爬的是第几页的内容。
爬下来的内容当中有几个需要注意的字段,下图中用黄框高亮出来了:
这几个字段的含义如下:
- question.title:问题的标题。
- content:回答的内容。
- voteup_count:赞同的数量。
这些字段在下一步筛选回答的时候会用到。
筛选回答
爬完数据后,我们来筛选一下结果。我们用 MongoDB 中的聚合管道对回答做筛选。
关于 MongoDB 的聚合管道的用法可以参考 Aggregation Pipeline Quick Reference 这篇文章:
https://www.smpeizi.com/manual/meta/aggregation-quick-reference/代码如下:
client = pymongo.MongoClient()db = client["zhihu"]items = www.pzzs168.com/db.answers.aggregate([ {"$match": {"target.type": "answer"}}, {"$match": {"target.voteup_count": {"$gte": 1000}}}, {"$addFields": {"answer_len": {"$strLenCP": "$target.content"}}}, {"$match": {"answer_len": {"$lte": 50}}},])上面的代码会筛选所有赞同大于 1000、字数小于 50 的回答,筛选出来的结果就是短小精辟的神回复。
以上是核心代码,完整代码已上传 GitHub:
https://www.aiidol.com/pythonml/answer知乎神回复
代码写完了,我们来运行下看看。由于关注者大部分是程序员,我们来筛选一下和程序员有关的神回复。