黑马程序员技术交流社区
标题: 【广州python】scikit-learn中的OneHotEncoder用法 [打印本页]
作者: 唐伯虎(0) 时间: 2019-9-26 15:14
标题: 【广州python】scikit-learn中的OneHotEncoder用法
OneHotEncoder 可用于将分类特征的每个元素转化为一个可直接计算的数值,也即特征值数字化,常用于特征工程中的数据预处理。
其本质是One-Hot编码在scikit-learn中的实现。
One-Hot
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候只有一位有效。
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值,然后,每个整数值被表示为二进制向量,将整数索引标记为1,其余都标为0。
sklearn 中的 OneHotEncoder
直达官网: sklearn.preprocessing.OneHotEncoder
基本参数:
# Encode categorical integer features as a one-hot numeric array.
OneHotEncoder(n_values=None,
categorical_features=None,
categories=None,
drop=None,
sparse=True,
dtype=np.float64,
handle_unknown='error')
示例:
#-*- coding: utf-8 -*-
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
enc.fit([[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]])
ans = enc.transform([[0, 1, 3]]).toarray()
'''
如果不加 toarray() 的话,输出的是稀疏的存储格式,即索引加值的形式,也可以通过参数指定 sparse = False 来达到同样的效果
'''
print(ans)
#输出 [[ 1. 0. 0. 1. 0. 0. 0. 0. 1.]]
解释:
对于输入数组,依旧是把每一行当作一个样本,每一列当作一个特征,
先来看第一个特征,即第一列 [0,1,0,1],也就是说它有两个取值 0 或者 1,那么 one-hot 就会使用两位来表示这个特征,[1,0] 表示 0, [0,1] 表示 1,在上例输出结果中的前两位 [1,0…] 也就是表示该特征为 0;
第二个特征,第二列 [0,1,2,0],它有三种值,那么 one-hot 就会使用三位来表示这个特征,[1,0,0] 表示 0, [0,1,0] 表示 1,[0,0,1] 表示 2,在上例输出结果中的第三位到第六位 […0,1,0,0…] 也就是表示该特征为 1;
第二个特征,第三列 [3,0,1,2],它有四种值,那么 one-hot 就会使用四位来表示这个特征,[1,0,0,0] 表示 0, [0,1,0,0] 表示 1,[0,0,1,0] 表示 2,[0,0,0,1] 表示 3,在上例输出结果中的最后四位 […0,0,0,1] 也就是表示该特征为 3;
注意:
在scikit-learn 0.20版本中有一个比较重要的改动,就是sklearn.preprocessing.OneHotEncoder 除了支持整数外,还支持字符串。
否则如果特征是字符串,就需要先使用 sklearn.preprocessing.LabelEncoder 将离散特征值转换为数字。
常用参数解释- n_values=’auto’
-(scikit-learn 0.20 中以categories替代,也即: categories=’auto’ )
表示每个特征使用几维的数值由数据集自动推断,即几种类别就使用几位来表示。当然也可以自己指定,示例:
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(categories= [2, 3, 4])
enc.fit([[0, 0, 3],
[1, 1, 0]])
ans = enc.transform([[0, 2, 3]]).toarray()
print(ans)
#输出 [[ 1. 0. 0. 0. 1. 0. 0. 0. 1.]]
drop=None
-用于从每个特征中舍去特定的分类,默认为None,且不能与categories、n_values同用。
dtype=np.float64
表示编码数值格式,默认是浮点型。
sparse=True
表示编码的格式,默认为 True,即为稀疏的格式,指定 False 则就不用 toarray() 了
handle_unknown=’error’
,其值可以指定为 “error” 或者 “ignore”,即如果碰到未知的类别,是返回一个错误还是忽略它。
categorical_features = 'all’
这个参数指定了对哪些特征进行编码,默认对所有类别都进行编码。也可以自己指定选择哪些特征,通过索引或者 bool 值来指定,看下例:
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(categorical_features = [0,2]) # 等价于 [True, False, True]
enc.fit([[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]])
ans = enc.transform([[0, 2, 3]]).toarray()
print(ans)
#输出 [[ 1. 0. 0. 0. 0. 1. 2.]]
以下为jupyter notebook 输出示例,可以看到运行结果之外,还有一串Warnings
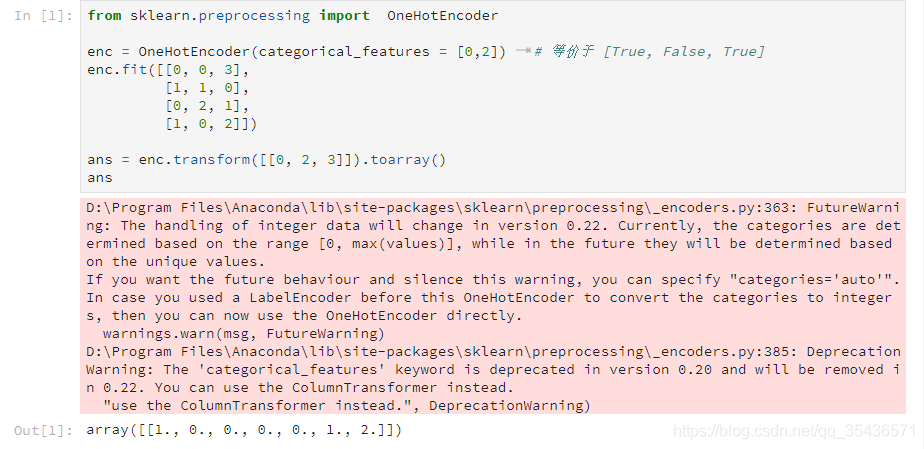
出现 警告的原因 是:
scikit-learn 0.20 中将此参数进行了剥离,后续的OneHotEncoder将不再支持categorical_features 参数,但新增了sklearn.compose.ColumnTransformer 类,
通过这个类我们可以对输入的特征分别做不同的预处理,并且最终的结果还在一个特征空间里面。
ColumnTransformer 的具体使用方法在此不再展开,
下面示例演示 利用OneHotEncoder结合ColumnTransformer ,实现categorical_features 参数 对指定的特征类编码
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
categorical_features = [0,2]
enc = OneHotEncoder(handle_unknown='ignore')
clt = ColumnTransformer([('name',enc,categorical_features)],remainder='passthrough')
clt.fit([[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]])
ans = clt.transform([[0, 2, 3]]) # 此处不能再使用toarray()
print(ans)
#输出 [[1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 2]]
[color=rgba(0, 0, 0, 0.75)]fit_transform()
[color=rgba(0, 0, 0, 0.75)]方法 transform( X ) 就是对 X 进行编码了。在实际应用中,我们更常用方法fit_transform( ) ,它相当于fit( X ).transform( X ) ,也就是一步到位,看下例:
[color=rgba(0, 0, 0, 0.749019607843137)]from sklearn.preprocessing import OneHotEncoder
[color=rgba(0, 0, 0, 0.749019607843137)]
[color=rgba(0, 0, 0, 0.749019607843137)]enc = OneHotEncoder(sparse = False)
[color=rgba(0, 0, 0, 0.749019607843137)]ans = enc.fit_transform([[0, 0, 3],
[color=rgba(0, 0, 0, 0.749019607843137)] [1, 1, 0],
[color=rgba(0, 0, 0, 0.749019607843137)] [0, 2, 1],
[color=rgba(0, 0, 0, 0.749019607843137)] [1, 0, 2]])
[color=rgba(0, 0, 0, 0.749019607843137)]
[color=rgba(0, 0, 0, 0.749019607843137)]print(ans)
[color=rgba(0, 0, 0, 0.749019607843137)] ''' 输出
[color=rgba(0, 0, 0, 0.749019607843137)] [[ 1. 0. 1. ..., 0. 0. 1.]
[color=rgba(0, 0, 0, 0.749019607843137)] [ 0. 1. 0. ..., 0. 0. 0.]
[color=rgba(0, 0, 0, 0.749019607843137)] [ 1. 0. 0. ..., 1. 0. 0.]
[color=rgba(0, 0, 0, 0.749019607843137)] [ 0. 1. 1. ..., 0. 1. 0.]]
[color=rgba(0, 0, 0, 0.749019607843137)] '''
结束:
以上只是OneHotEncoder的基本用法演示,更多高级的应用,有待进一步研究学习。
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) |
黑马程序员IT技术论坛 X3.2 |