1. 单向同步, mysql/oracle互相同步
2. 双向同步,无冲突变更
3. 文件同步,本地/aranda文件
4. 双A同步,冲突检测&冲突补救
5. 数据迁移,中间表/行记录同步
导历史表还需要程序代码实现吗? 还在用mysql的主从复制吗? Otter都能为你解决。
典型的场景是账户信息表和账户交易明细表,更新账户余额后需要登记一条账户明细,并且保证在一个事务里,用户可以通过交易明细表查看交易记录,但是交易明细表的数据量是逐步递增的,用户量多的系统,几个月下来的数据超过千万了,表数据量一多就导致查询和插入变慢,而一开始就对账户明细做分表处理就难于保证强一致性事务,通过otter可以将记录同步导历史表,并且进行分表处理,用户往年的交易记录就可以查询历史表了,而原交易明细表就可以删除一个月甚至几天前的数据;
实际测试中,otter的同步速度相比于mysql的复制,约有5倍左右的性能提升,这取决于其同步算法的实现. 抛弃了强一致性,得到了性能提升。
二、官方安装文档https://github.com/alibaba/otter/wiki/Manager_Quickstart
https://github.com/alibaba/otter/wiki/Node_Quickstart
演示视频:http://video.tudou.com/v/XMTc4NjU1MjM4NA==.html
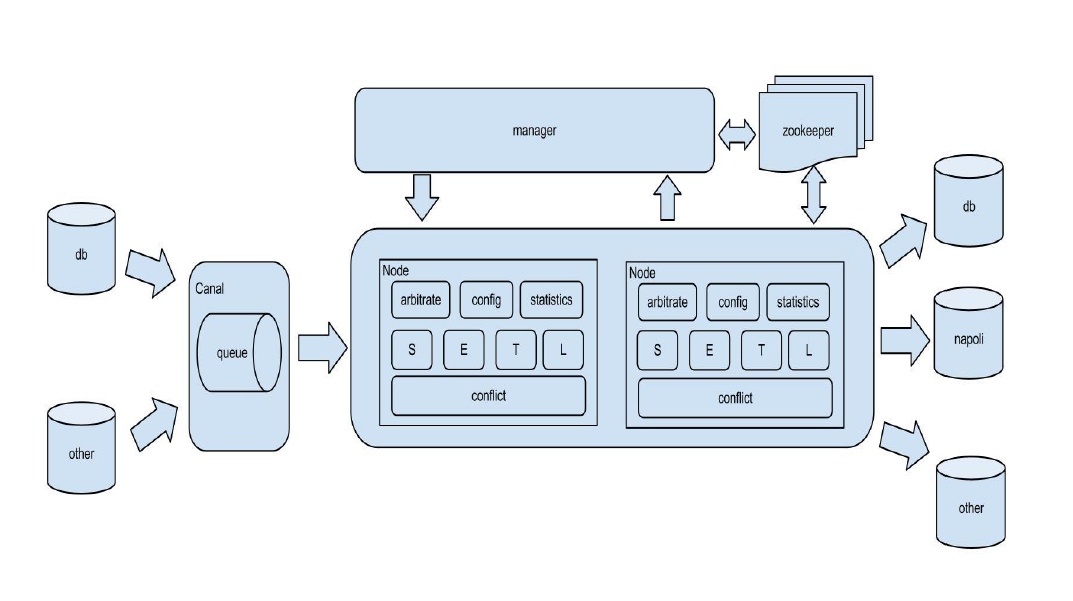
三、整体架构
原理描述:
基于Canal开源产品,获取数据库增量日志数据。
典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
名词解释:
Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成;Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成;
DataMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等;
DataMedia: 抽象的数据介质概念,可以理解为数据表/mq队列定义;
DataMediaSource: 抽象的数据介质源信息,补充描述DateMedia;
ColumnPair: 定义字段映射关系;
ColumnGroup: 定义字段映射组;
Node: 处理同步过程的工作节点,对应一个jvm;
四、环境准备1. otter manager依赖于mysql进行配置信息的存储,所以需要预先安装mysql,并初始化otter manager的系统表结构
a. 安装mysql
b. 初始化otter manager系统表:https://raw.github.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
2. 整个otter架构依赖了zookeeper进行多节点调度,所以需要预先安装zookeeper,不需要初始化节点,otter程序启动后会自检.
manager需要在otter.properties中配置zookeeper集群机器
3. 安装jdk1.6+
五、下载安装下载页面:https://github.com/alibaba/otter/releases/
下载manager:wget https://github.com/alibaba/otter/releases/download/v4.2.14/manager.deployer-4.2.14.tar.gz
创建manager目录 : mkdir ~/manager
tar zxvf manager.deployer-4.2.14.tar.gz -C ~/manager
下载node: wget https://github.com/alibaba/otter/releases/download/v4.2.14/node.deployer-4.2.14.tar.gz
创建node目录: mkdir ~ /node
tar zxvf node.deployer-4.2.14.tar.gz -C ~ /node
六、修改配置文件运行(1) Manager
1) otter.properties配置修改 vi ~/manager/conf/otter.properties
##修改为正确访问ip,生成URL使用,node的配置需要用到
otter.domainName= 127.0.0.1
##manage页面的访问端口
otter.port =8080
##修改为正确数据库信息
otter.database.driver.class.name = com.mysql.jdbc.Driver
otter.database.driver.url = jdbc:mysql://127.0.01:3306/ottermanager
otter.database.driver.username = root
otter.database.driver.password = hello
##为node连接manager的端口, node的配置需要用到
otter.communication.manager.port= 1099
##配置zookeeper集群机器
otter.zookeeper.cluster.default= 127.0.0.1:2181
其它使用默认配置即可
2) Manager启动
Linux : sh ~/manager/bin/startup.sh
Windows:startup.bat
查看日志: vi ~/manager/logs/manager.log
启动成功后浏览器访问http://127.0.0.1:8080,出现otter的页面
访问:http://127.0.0.1:8080/login.htm,初始密码为:admin/admin,即可完成登录. 目前:匿名用户只有只读查看的权限,登录为管理员才可以有操作权限
3) 关闭manager
sh ~/manager/bin/stop.sh
(2)Node
node会受ottermanager进行管理,所以需要预先安装otter manager,完成manager安装后,需要在manager页面为node定义配置信息,并生一个唯一id。
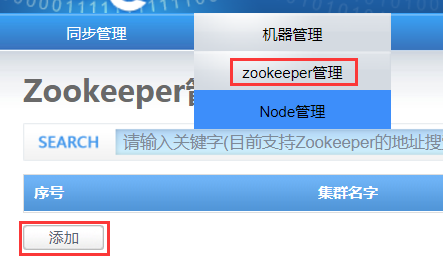
1) 添加zookeeper
首先确保你的zookeeper已启动成功。
otter依赖zookeeper,访问manager页面的机器管理页面,选择菜单进入“机器管理→zookeeper管理”页面:
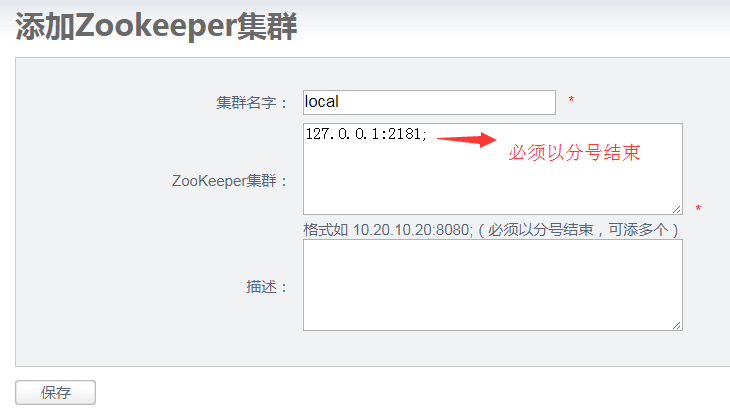
点击添加进入“添加Zookeeper集群”页面
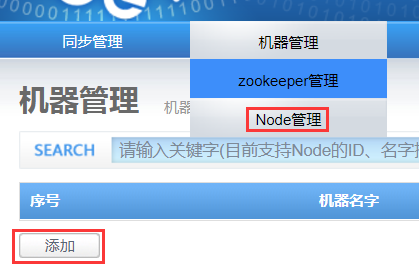
2) 添加node
Zookeeper添加成功后,进入“机器管理→Node管理”页面:
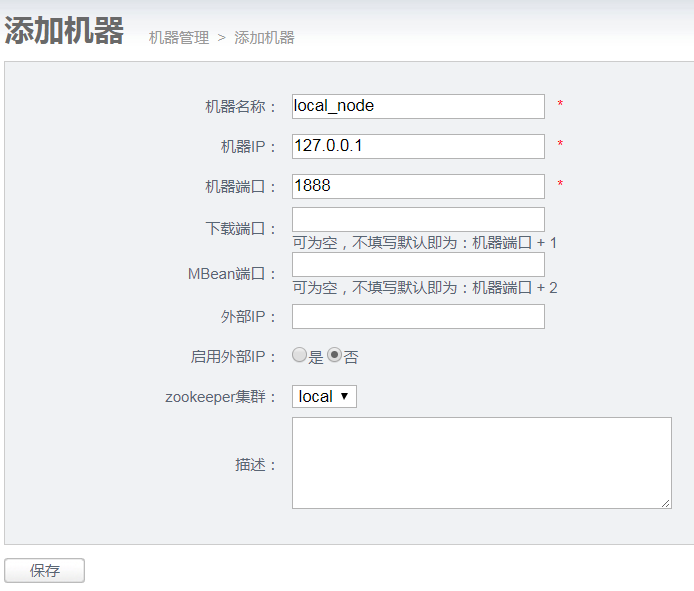
点击添加进入添加机器页面
3) 配置nid
机器添加完成后,跳转到机器列表页面,获取对应的机器序号nid:
通过这几步操作,获取到了node节点对应的唯一标示,称之为node id,简称nid,比如我添加的机器对应序号为1
执行echo 1 >~/node/conf/nid , 保存到conf目录下的nid文件;
4) otter.properties配置修改 vi ~/otter/conf/otter.properties
# node的安装目录
otter.nodeHome = ${user.dir}/node
#manager的服务地址
otter.manager.address = 127.0.0.1:1099
5) 启动
Linux:sh~/node/bin/startup.sh
Windows:startup.bat
打开日志: vi ~/node/logs/node/node.log,出现以下的错误,表示manager页面的ip配置不正确,此时修改ip为对应的host ip后,再次启动即可。
访问: http://127.0.0.1:8080/,查看“机器管理-Node管理”页面,对应的节点状态,如果变为了已启动,代表已经正常启动。
关闭:sh ~/node/bin/stop.sh
七、配置一个同步任务搭建一个数据库同步任务,源数据库必须开启binlog,并且binlog_format为ROW,即在mysql的配置文件加上以下两行
log-bin=mysql-bin
binlog-format=ROW
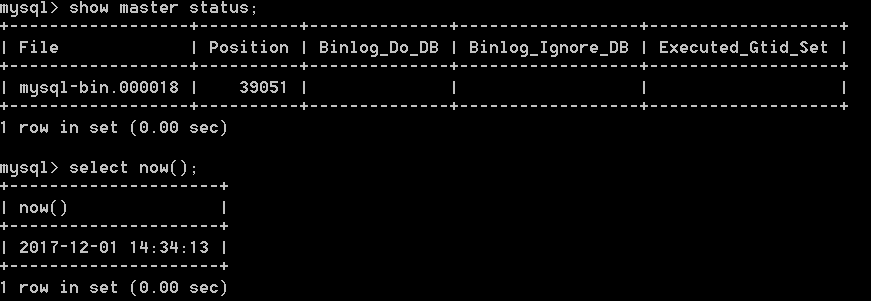
如果源库已开启binlog,通过mysql客户端命令show master status查看
1. 添加canal
Otter使用canal开源产品获取数据库增量日志数据,可以把cannal看作是源库的一个伪slave。
原理: canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议,mysql master收到dump请求,开始推送binarylog给slave(也就是canal), canal解析binary log对象(原始为byte流)。
Canal官方文档:https://github.com/alibaba/canal/wiki
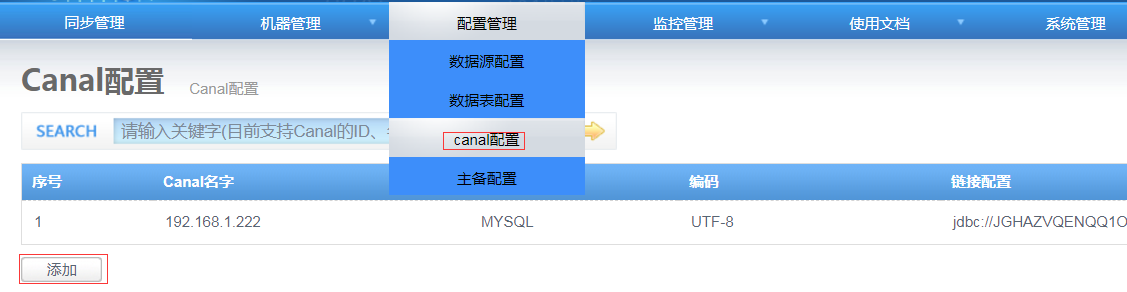
1) 在Otter Manager“配置管理-canal配置”页面点击添加:
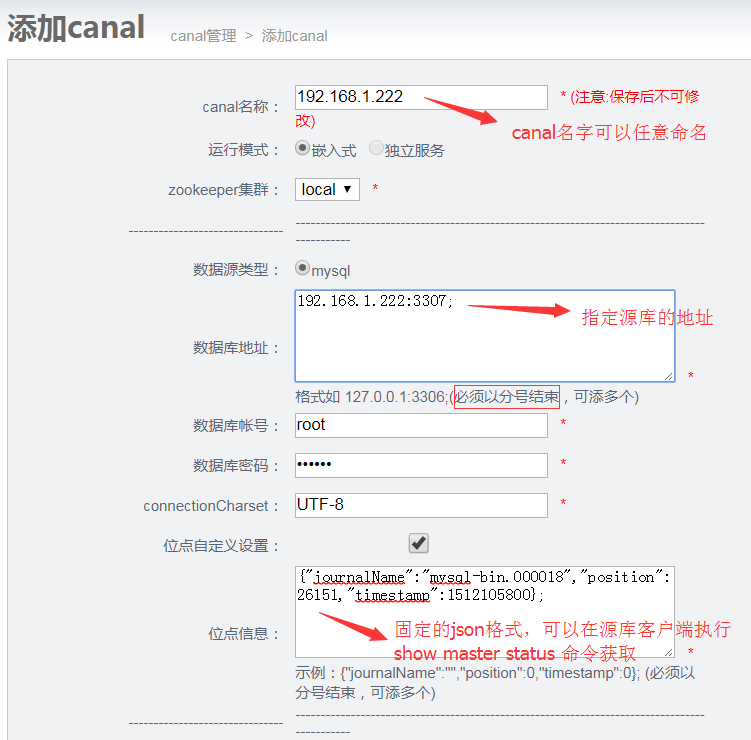
2) 进入添加cannal页面:
Node集成了cannal,所以不需要单独下载cannal;
Cannal 存储机制分为memory和file,也可以在运行模式选项选择作为独立服务运行;
勾选其他参数设置,可以设置cannal的服务端口;
必须配置位点信息,否则如果你的数据库已有存量数据,第一次运行时需要等待比较长的时间,可以通过连接源库客户端执行sql获取,如下:
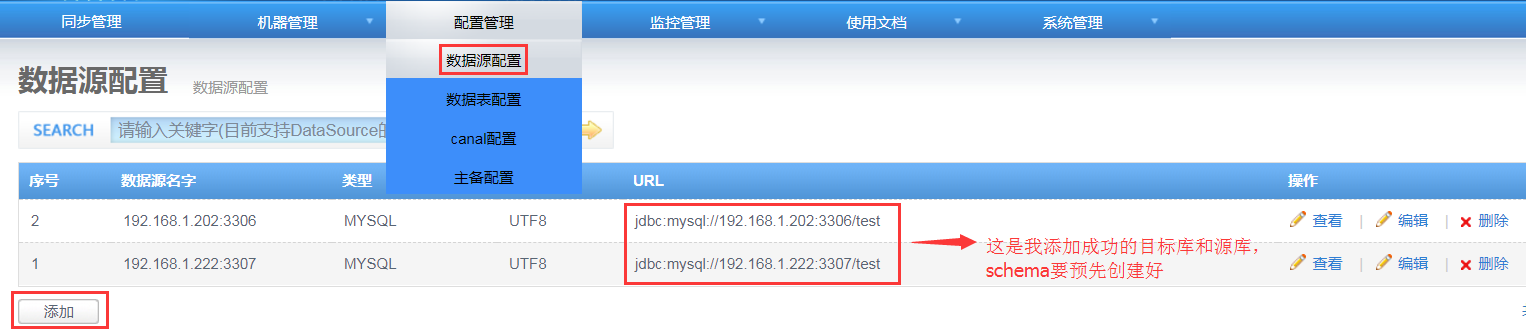
2. 添加数据源
源库和目标库的schema需要一致,不然无法执行ddl语句
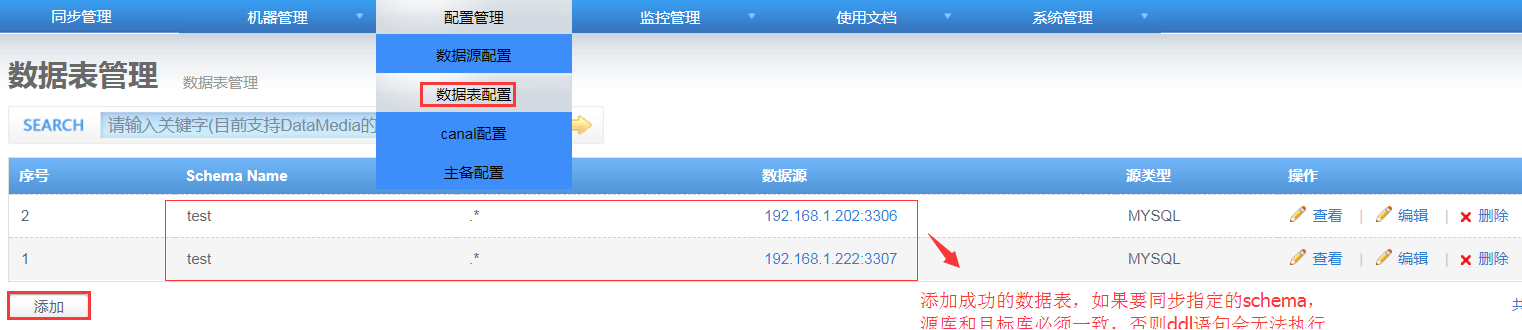
3. 添加数据表配置
“配置管理-数据表配置”进入数据表管理页面:
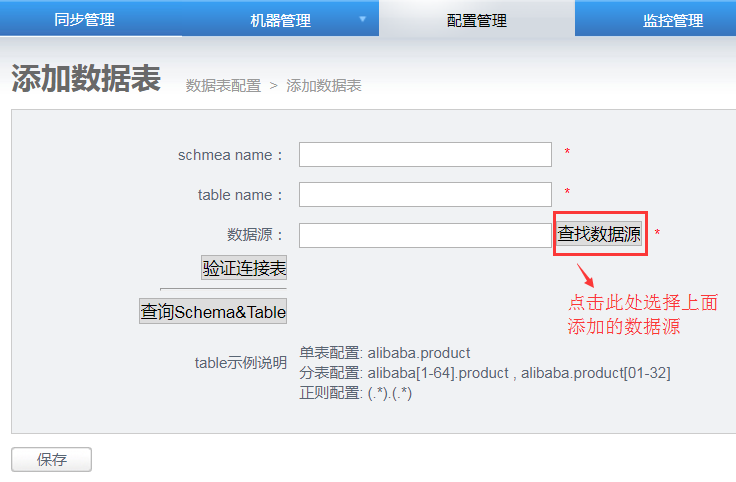
点击添加,进入添加数据表页面:
table示例说明
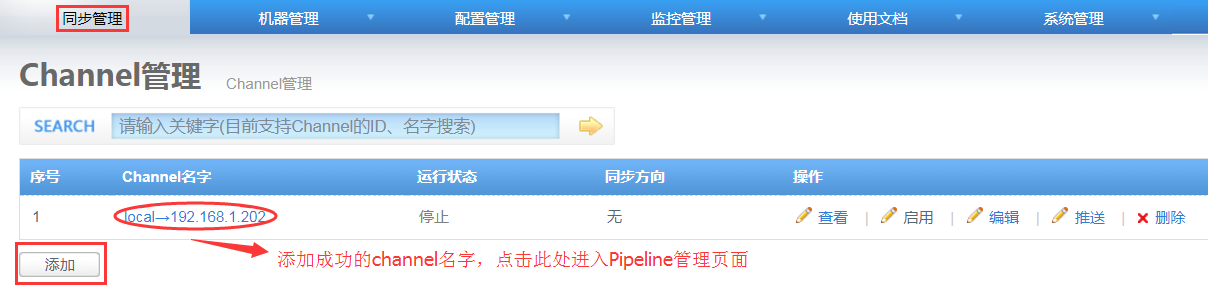
4. 添加一个channel
如下图,点击添加按钮进入添加channel页面,输入Channel Name后保存,则成功添加一个channel;
5. 配置一个pipeline
添加channel成功后,点击Channel名字,进入Pipeline管理页面,添加一个pipeline;
进入添加pipeline页面
如上图填好所需信息,勾选高级设置,可以选是否过滤ddl同步等选项,点击保存,成功后会返回Pipeline管理页面。
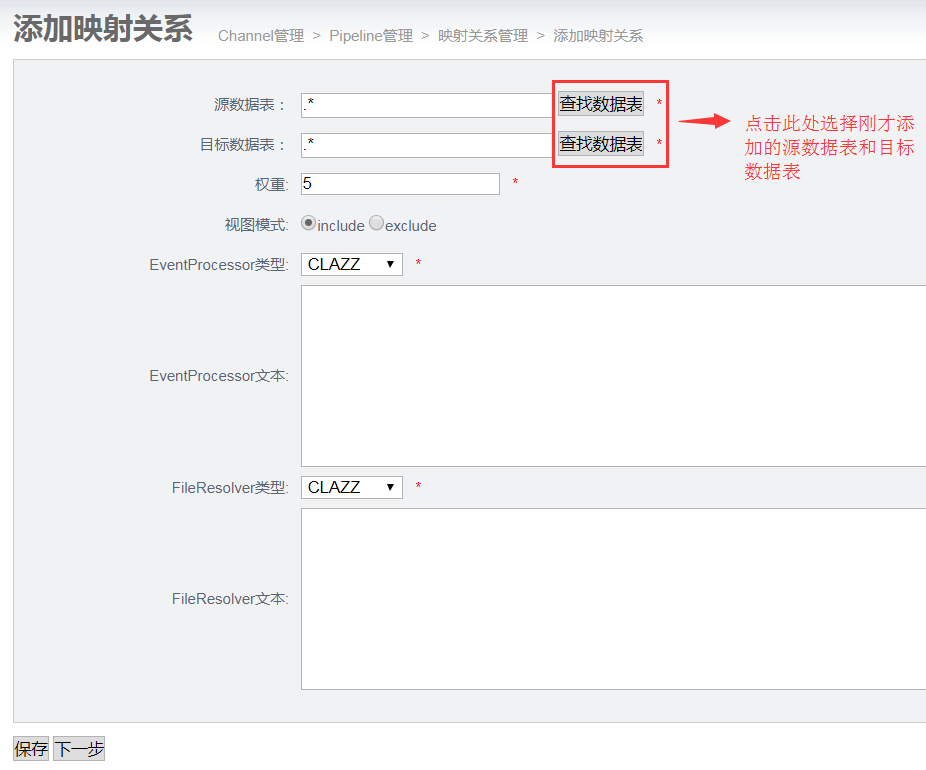
6. 添加映射关系
添加pipeline成功后,点击Pipeline名字
进入映射关系列表页面,点击添加
进入添加映射关系页面
点击保存返回映射关系列表页面,如果源数据表是只同步一个表可以点击下一步,选择需要同步的字段映射关系;
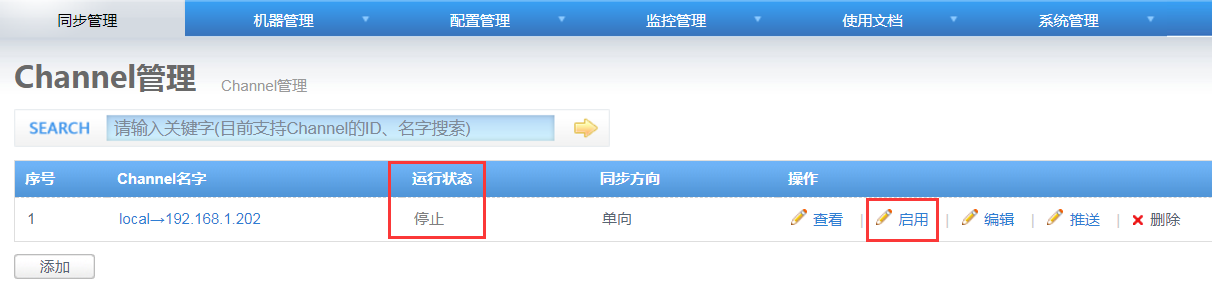
7. 启用同步
以上配置,一个简单的同步任务就完成了,返回Channel管理页面
点击“启用”,运行状态就变为“运行”;
现在可以新增一个表,插入记录,查看数据是否同步过去了。
点击Channel名字,进入Pineline管理页面,可点击“监控”查看同步状态
转自:https://blog.csdn.net/qq_28710983/article/details/81027148
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |