黑马程序员技术交流社区
标题: 【成都校区*文章*】线程池的使用 [打印本页]
作者: 小蜀哥哥 时间: 2020-1-2 19:32
标题: 【成都校区*文章*】线程池的使用
线程池的使用
我们有两种常见的创建线程的方法,一种是继承Thread类,一种是实现Runnable的接口,Thread类其实也是实现了Runnable接口。但是我们创建这两种线程在运行结束后都会被虚拟机销毁,如果线程数量多的话,频繁的创建和销毁线程会大大浪费时间和效率,更重要的是浪费内存,因为正常来说线程执行完毕后死亡,线程对象变成垃圾!那么有没有一种方法能让线程运行完后不立即销毁,而是让线程重复使用,继续执行其他的任务哪?我们使用线程池就能很好地解决这个问题。
一.线程池家族
线程池的最上层接口是Executor,这个接口定义了一个核心方法execute(Runnabel command),这个方法最后被ThreadPoolExecutor类实现,这个方法是用来传入任务的。而且ThreadPoolExecutor是线程池的核心类,此类的构造方法如下:
[url=]
[Java] 纯文本查看 复制代码
[/url]
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue); public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory); public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler); public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);[url=]
构造方法的参数及意义:
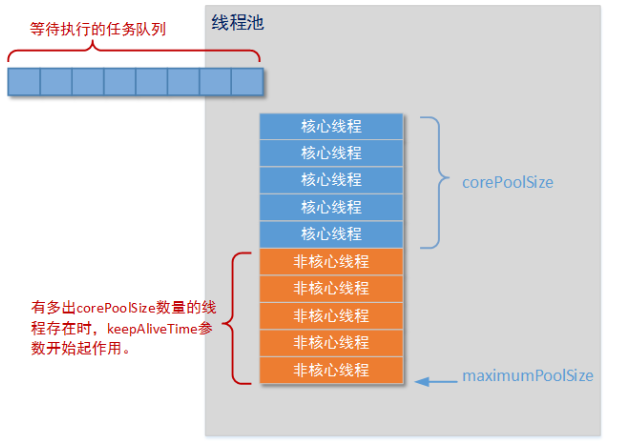
corePoolSize:核心线程池的大小,如果核心线程池有空闲位置,这是新的任务就会被核心线程池新建一个线程执行,执行完毕后不会销毁线程,线程会进入缓存队列等待再次被运行。
maximunPoolSize:线程池能创建最大的线程数量。如果核心线程池和缓存队列都已经满了,新的任务进来就会创建新的线程来执行。但是数量不能超过maximunPoolSize,否侧会采取拒绝接受任务策略,我们下面会具体分析。
keepAliveTime:非核心线程能够空闲的最长时间,超过时间,线程终止。这个参数默认只有在线程数量超过核心线程池大小时才会起作用。只要线程数量不超过核心线程大小,就不会起作用。
unit:时间单位,和keepAliveTime配合使用。
workQueue:缓存队列,用来存放等待被执行的任务。
threadFactory:线程工厂,用来创建线程,一般有三种选择策略。
[Java] 纯文本查看 复制代码
ArrayBlockingQueue;
LinkedBlockingQueue;
SynchronousQueue;
handler:拒绝处理策略,线程数量大于最大线程数就会采用拒绝处理策略,四种策略为
[Java] 纯文本查看 复制代码
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
Executor接口有一个子接口ExecutorService,ExecutorService的实现类为AbstracExecutorService,而ThreadPoolExcutor正是AbstrcExecutorService的子类。
ThreadPoolExecutor还有两个常用的方法shutdown和submit,两者都用来关闭线程池,但是后者有一个结果返回。
二.线程池实现原理
线程池图:
1.线程池状态
线程池和线程一样拥有自己的状态,在ThreadPoolExecutor类中定义了一个volatile变量runState来表示线程池的状态,线程池有四种状态,分别为RUNNING、SHURDOWN、STOP、TERMINATED。
线程池创建后处于RUNNING状态。
调用shutdown后处于SHUTDOWN状态,线程池不能接受新的任务,会等待缓冲队列的任务完成。
调用shutdownNow后处于STOP状态,线程池不能接受新的任务,并尝试终止正在执行的任务。
当线程池处于SHUTDOWN或STOP状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为TERMINATED状态。
2.线程池任务的执行
当执行execute(Runnable command)方法后,传入了一个任务,我们看一下execute方法的实现原理。
[url=][/url]
[Java] 纯文本查看 复制代码
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
if (runState == RUNNING && workQueue.offer(command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
else if (!addIfUnderMaximumPoolSize(command))
reject(command);
}
}
整个方法的执行过程是这样的,首先判断任务是否为空,空抛空指针异常,否则执行下一个判断,如果目前线程的数量小于核心线程池大小,就执行addIfUnderCorePollSize(command)方法,在核心线程池创建新的线程,并且执行这个任务。
我们看这个方法的具体实现:
[Java] 纯文本查看 复制代码
private boolean addIfUnderCorePoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (poolSize < corePoolSize && runState == RUNNING)
t = addThread(firstTask); //创建线程去执行firstTask任务
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start();
return true;
}
这个方法首先是获取线程池的锁,参考别人的博客,说是和线程池状态有关,没有搞懂......,后面又进行一次判断,判断线程池线程数量和核心线程池的比较,前面execute()已经判断过,这里为什么还要进行判断哪?因为我们执行完Execute()中的判断后,可能有新的任务进来了,并且为这个任务在核心线程池创建了新的线程去执行,如果刚好这是核心线程池满了,那么就不能再加入新的县城到核心线程池了。这种可能性是存在的,因为你不知道cpu什么时间分配给谁,所以我们要加一个判断,至于线程池状态为什么也要判断,也是因为可能有其他线程执行了shutdown或者shutdownNow方法,导致线程池状态不是RUNNING,那么线程池就停止接收新的任务,也就不会创建新的线程去执行这个任务了。
t=addThread(firstTask);这句代码至关重要,我们看方法的实现代码:
[url=][/url]
[Java] 纯文本查看 复制代码
private Thread addThread(Runnable firstTask) {
Worker w = new Worker(firstTask);
Thread t = threadFactory.newThread(w); //创建一个线程,执行任务
if (t != null) {
w.thread = t; //将创建的线程的引用赋值为w的成员变量
workers.add(w); //将当前任务添加到任务集
int nt = ++poolSize; //当前线程数加1
if (nt > largestPoolSize)
largestPoolSize = nt;
}
return t;
}
这个方法返回类型是Thread,所以我们可以新建一个线程并执行任务,之后将线程对象返回给外面的线程对象,然后执行t.start(),我们看到有一个Worker对象接收了任务,我们看Worker类的实现:
[url=][/url]
[Java] 纯文本查看 复制代码
private final class Worker implements Runnable {
private final ReentrantLock runLock = new ReentrantLock();
private Runnable firstTask;
volatile long completedTasks;
Thread thread;
Worker(Runnable firstTask) {
this.firstTask = firstTask;
}
boolean isActive() {
return runLock.isLocked();
}
void interruptIfIdle() {
final ReentrantLock runLock = this.runLock;
if (runLock.tryLock()) {
try {
if (thread != Thread.currentThread())
thread.interrupt();
} finally {
runLock.unlock();
}
}
}
void interruptNow() {
thread.interrupt();
}
private void runTask(Runnable task) {
final ReentrantLock runLock = this.runLock;
runLock.lock();
try {
if (runState < STOP &&
Thread.interrupted() &&
runState >= STOP)
boolean ran = false;
beforeExecute(thread, task); //beforeExecute方法是ThreadPoolExecutor类的一个方法,没有具体实现,用户可以根据
//自己需要重载这个方法和后面的afterExecute方法来进行一些统计信息,比如某个任务的执行时间等
try {
task.run();
ran = true;
afterExecute(task, null);
++completedTasks;
} catch (RuntimeException ex) {
if (!ran)
afterExecute(task, ex);
throw ex;
}
} finally {
runLock.unlock();
}
}
public void run() {
try {
Runnable task = firstTask;
firstTask = null;
while (task != null || (task = getTask()) != null) {
runTask(task);
task = null;
}
} finally {
workerDone(this); //当任务队列中没有任务时,进行清理工作
}
}
}
这个类实现了Runnable接口,所以会有run()方法,我们看到run中执行的还是传入的任务,其实相当于调用传入任务对象的run方法,我们之所以费力气将任务对象加到Worker类中去执行,是因为这个线程执行之后会进入阻塞队列等待被执行,这个线程的生命并没有结束,这也正是我们使用线程池的最大原因。我们用一个Set集合存储Worker,这样不会有重复的任务被存储,firstTask被执行完后进入缓存队列,而这个新创建的线程就一直从缓存队列中拿到任务去执行。这个方法为getTask(),所以我们来看看线程如何从缓存队列拿到任务。
[url=][/url]
[Java] 纯文本查看 复制代码
Runnable getTask() {
for (;;) {
try {
int state = runState;
if (state > SHUTDOWN)
return null;
Runnable r;
if (state == SHUTDOWN) // Help drain queue
r = workQueue.poll();
else if (poolSize > corePoolSize || allowCoreThreadTimeOut) //如果线程数大于核心池大小或者允许为核心池线程设置空闲时间,
//则通过poll取任务,若等待一定的时间取不到任务,则返回null
r = workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS);
else
r = workQueue.take();
if (r != null)
return r;
if (workerCanExit()) { //如果没取到任务,即r为null,则判断当前的worker是否可以退出
if (runState >= SHUTDOWN) // Wake up others
interruptIdleWorkers(); //中断处于空闲状态的worker
return null;
}
// Else retry
} catch (InterruptedException ie) {
// On interruption, re-check runState
}
}
}
我们看到如果核心线程池中创建的线程想要拿到缓存队列中的任务,先要判断线程池的状态,如果STOP或者TERMINATED,返回NULL,如果是RUNNING或者SHUTDOWN,则从缓存队列中拿到任务去执行。
这就是核心线程池执行任务的原理。
那么如果线程数量超过核心线程池大小哪?我们回到executor()方法,如果发生这种情况,处理方式是
[AppleScript] 纯文本查看 复制代码
if (runState == RUNNING && workQueue.offer(command))
这段代码意思是,如果线程数量超过核心线程池大小,先进行线程池状态的判断,如果是RUNNING,则将新进来的线程加入缓存队列。如果失败,往往是因为缓存队列满了或者线程池状态不是RUNNING,就直接创建新的线程去执行任务,调用addIfUnderMaximumPoolSize(command),就会新创建线程,但是这个县城不是核心线程池中的,是临时扩展的,要保证线程数最大不超过线程池大小 maximumPoolSize,如果超过执行 reject(command);操作,拒绝接受新的任务。
还有如果任务已经加入缓存队列成功还要继续进行判断
[AppleScript] 纯文本查看 复制代码
if (runState != RUNNING || poolSize == 0)
这是为了防止在将任务加入缓存队列的同时其他线程调用shutdown或者shutdownNow方法,所以采取了保护措施
[AppleScript] 纯文本查看 复制代码
ensureQueuedTaskHandled(command)
我们看addIfUnderMaximumPoolSize的实现方法:
[url=][Java] 纯文本查看 复制代码
[/url]
private boolean addIfUnderMaximumPoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (poolSize < maximumPoolSize && runState == RUNNING)
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start();
return true;
}
[url=]
这个方法和addIfUnderCorePoolSize基本一样,只是方法中判断条件改变了,这个方法是在缓冲队列满了并且线程池状态是在RUNNING状态下才会执行,里面的判断条件是线程池数量小于线程池最大容量,并且线程池状态是RUNNING。
我们进行总结:
- 如果当前线程池中的线程数目小于corePoolSize,则每来一个任务,就会创建一个线程去执行这个任务;
- 如果当前线程池中的线程数目>=corePoolSize,则每来一个任务,会尝试将其添加到任务缓存队列当中,若添加成功,则该任务会等待空闲线程将其取出去执行;若添加失败(一般来说是任务缓存队列已满),则会尝试创建新的线程去执行这个任务;
- 如果当前线程池中的线程数目达到maximumPoolSize,则会采取任务拒绝策略进行处理;
- 如果线程池中的线程数量大于 corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止,直至线程池中的线程数目不大于corePoolSize;如果允许为核心池中的线程设置存活时间,那么核心池中的线程空闲时间超过keepAliveTime,线程也会被终止。
三.线程池使用示例
[url=][Java] 纯文本查看 复制代码
[/url]
package cn.yqg.java;
public class Task implements Runnable{
private int num;
public Task(int num) {
this.num=num;
}
@Override
public void run() {
System.out.println("正在执行任务 "+num);
try {
Thread.currentThread().sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程"+num+"执行完毕");
}
}
[Java] 纯文本查看 复制代码
package cn.yqg.java;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class Test4 {
public static void main(String[] args) {
ThreadPoolExecutor pool=new ThreadPoolExecutor(5,10,200, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(5));
for(int i=0;i<15;i++) {
Task task=new Task(i);
pool.execute(task);
System.out.println("线程池中线程数目:"+pool.getPoolSize()+",队列中等待执行的任务数目:"+
pool.getQueue().size()+",已执行玩别的任务数目:"+pool.getCompletedTaskCount());
}
pool.shutdown();
}
}
一种可能情况:
[Java] 纯文本查看 复制代码
正在执行任务 0
线程池中线程数目:1,队列中等待执行的任务数目:0,已执行玩别的任务数目:0
线程池中线程数目:2,队列中等待执行的任务数目:0,已执行玩别的任务数目:0
线程池中线程数目:3,队列中等待执行的任务数目:0,已执行玩别的任务数目:0
正在执行任务 1
正在执行任务 2
线程池中线程数目:4,队列中等待执行的任务数目:0,已执行玩别的任务数目:0
正在执行任务 3
线程池中线程数目:5,队列中等待执行的任务数目:0,已执行玩别的任务数目:0
线程池中线程数目:5,队列中等待执行的任务数目:1,已执行玩别的任务数目:0
正在执行任务 4
线程池中线程数目:5,队列中等待执行的任务数目:2,已执行玩别的任务数目:0
线程池中线程数目:5,队列中等待执行的任务数目:3,已执行玩别的任务数目:0
线程池中线程数目:5,队列中等待执行的任务数目:4,已执行玩别的任务数目:0
线程池中线程数目:5,队列中等待执行的任务数目:5,已执行玩别的任务数目:0
线程池中线程数目:6,队列中等待执行的任务数目:5,已执行玩别的任务数目:0
正在执行任务 10
线程池中线程数目:7,队列中等待执行的任务数目:5,已执行玩别的任务数目:0
正在执行任务 11
线程池中线程数目:8,队列中等待执行的任务数目:5,已执行玩别的任务数目:0
正在执行任务 12
线程池中线程数目:9,队列中等待执行的任务数目:5,已执行玩别的任务数目:0
正在执行任务 13
线程池中线程数目:10,队列中等待执行的任务数目:5,已执行玩别的任务数目:0
正在执行任务 14
线程2执行完毕
线程1执行完毕
线程4执行完毕
线程3执行完毕
正在执行任务 8
线程0执行完毕
正在执行任务 9
正在执行任务 7
正在执行任务 6
正在执行任务 5
线程12执行完毕
线程13执行完毕
线程11执行完毕
线程10执行完毕
线程14执行完毕
线程7执行完毕
线程9执行完毕
线程8执行完毕
线程5执行完毕
线程6执行完毕
| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) |
黑马程序员IT技术论坛 X3.2 |