搞了几个月的自动化测试,结果不甚理想,这里做一个简单的总结。
为什么要做自动化测试呢?因为手工测试效率低,找 case、执行 case 太费时间。
为什么自动化测试前面要加“模块级别”呢?因为一个系统依赖很多外部系统,如果不能有效屏蔽外部环境的差异,自动化测试会经常因为环境问题而失败。
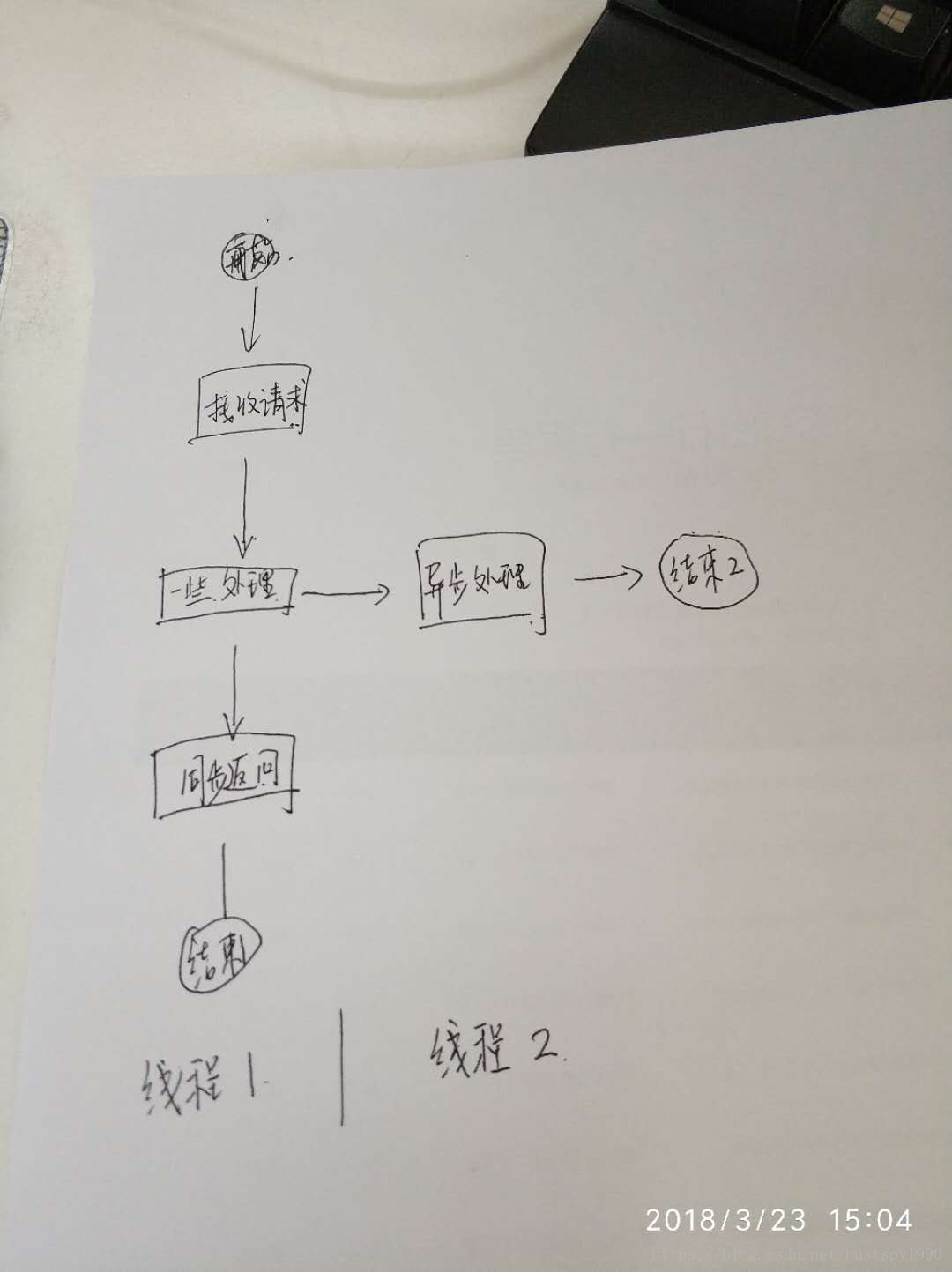
原理这里讲的自动化测试原理是,在线上环境录制测试 case,在线下测试环境利用录制的 case 进行回放测试。
如何录制 case?某个系统对一次请求的一次处理可以认为是一个 case,模块级别的自动化测试要求录制该系统在处理请求时的所有对外交互,包括但不限于:
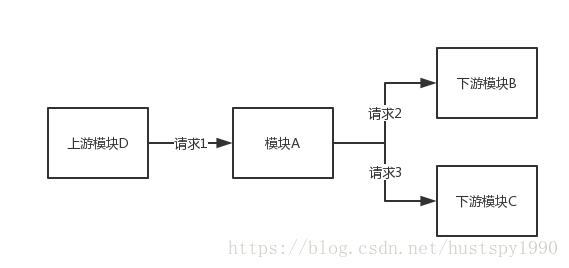
以下图为例,有 A、B、C、D 四个系统模块,假设要对模块 A 做自动化测试,需要录制测试 case。该模块有一个接口,接收来自模块 D 的请求,在处理过程中会产生对模块 B、C 的下游调用。那么在录制 case 时,不仅要录制该接口的输入输出,也有录制两次下游调用的输入和输出。
在请求处理过程中,往往会出现各种线程的切换、异步调用,如何将一个请求的所有对外交互串起来呢?很多公司都有分布式链路跟踪系统,会有一个 traceID 能够把不同系统的请求串联起来,同理也可以利用该 traceID 把单个系统内部的请求处理过程串联起来,拥有同一个 traceID 的输入输出可以认为是属于同一个 case 的。
case 的录制思路比较简单,收集数据后存储到 DB 中即可。case 的回放测试分为两步:
前面说了,录制 case 时,需要录制所有的下游调用的请求和响应。对于需要定期更新的本地缓存,也需要 dump 其数据,如何 dump 呢?dump 查缓存的方法即可,以下面代码为例,dump 方法 getXXXConfig 的输入输出即可。本质上是将 getXXXConfig 方法的调用当成了外部请求进行录制。
@Component
public class XXXCache {
private LoadingCache<String, List<XXX>> xxxCache = CacheBuilder.newBuilder().maximumSize(10000).expireAfterWrite(5, TimeUnit.MINUTES).build(
new CacheLoader<String, List<XXX>>() {
public List<XXX> load(String key) {
// 省略
}
});
public List<XXX> getXXXConfig(String param) {
try {
return xxxCache.get(param);
}catch (Exception e) {
logger.error("get xxx error, param:{}", e, param);
}
return ListUtils.EMPTY_LIST;
}
}
性能问题
收集数据必定会耗费一些性能,为了减轻对系统的压力,录制时增加了采样率的概念,只录制少量数据。
多数情况下,降低采样率可以解决性能问题,但也有例外。在对接某个系统时发现其有性能问题,CPU 从 20% 涨到了 30%,发现一次请求里要录制 5000 条下游调用,我们将采样率降低到 10 分钟录制一个 case 依然无法解决问题。那么到底是哪里耗费性能呢?研究后发现,是在判断是否收集数据的方法里比较耗费性能,该方法在每次有下游调用时都需要用来判断是否需要收集数据。该方法代码如下所示,其中有两点影响性能:
在低并发的情况下,ConcurrentHashMap 竞争较少影响不大,然而在高并发情况下竞争较多,性能下降。
inRecordEnv 是一个 volatile 变量,会引起 CPU 缓存失效,少量影响不大,但是一次请求里 5000 次 CPU 缓存失效影响就大了。
public volatile boolean inRecordEnv;
public ConcurrentHashMap<String, TraceContext> recordingTraceIdMap;
public boolean needRecord(String traceId) {
if (! inRecordEnv) {
return false;
}
return recordingTraceIdMap.contains(traceId);
}
解决该问题的办法有两个:
将是否需要录制放到线程本地变量中,跟 traceID 一起传递,这需要改到分布式链路跟踪组件。
case 录制一般是选择集群中的某一台服务器进行录制的,那么修改负载均衡机制,降低录制 case 集群的权重,即可减轻其压力。同时,需要稍作处理,让其他机器需要不走录制判断逻辑,毕竟单单是录制判断逻辑就足以影响性能了。
静态方法、随机数问题
有一些缓存的查询用的是静态方法,静态方法因为不被 Spring 容器托管,是无法使用 Spring AOP 处理的。对于此类方法,如果要 dump 数据,就必须使用 java instrument 字节码修改技术。
与之类似的还有随机数生成器、UUID 生成,这些随机数往往是某个 Redis 值的 key,也需要去 mock 住才能保证测试成功。
带异步任务的请求结束时间判断问题
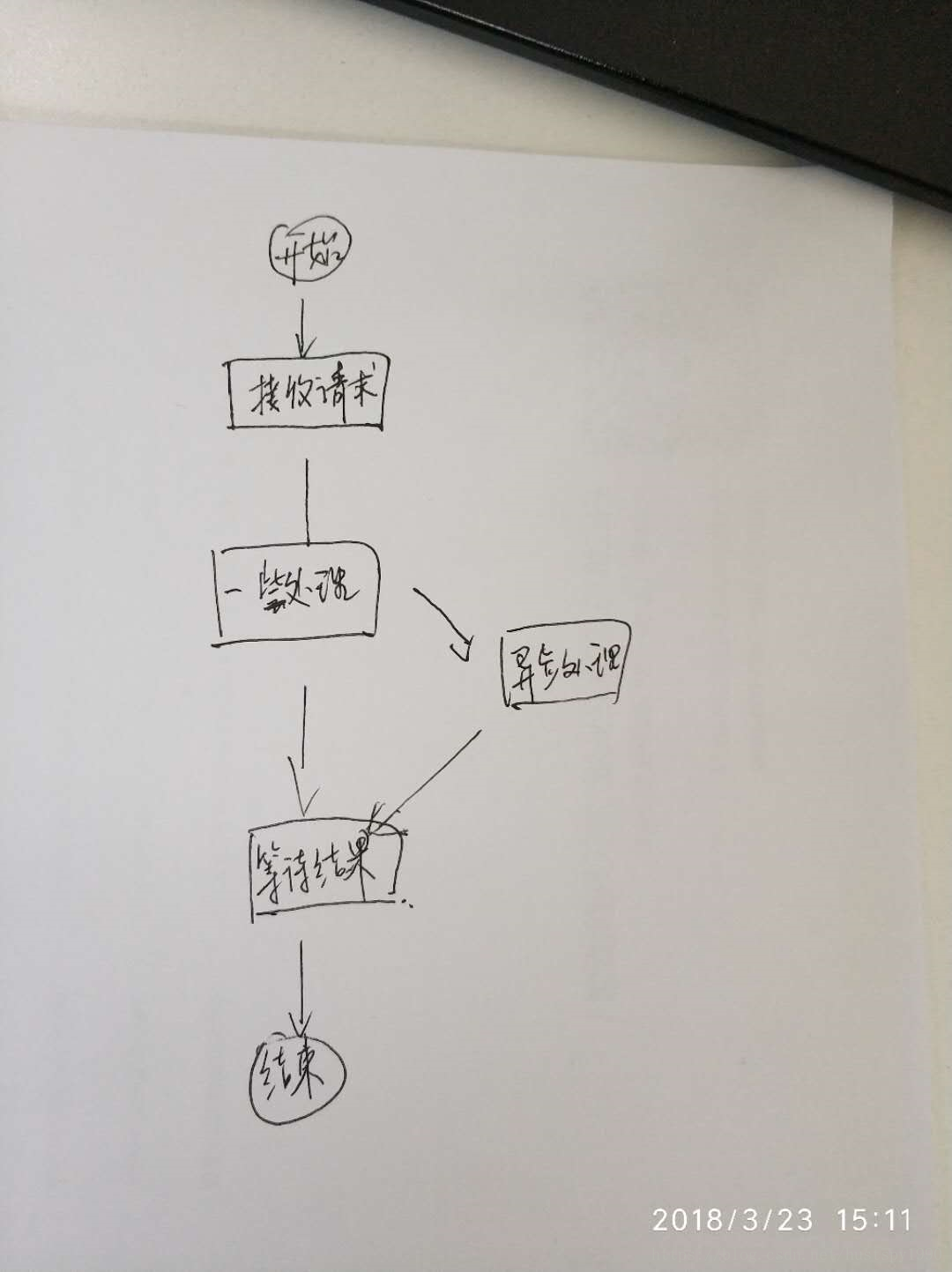
在业务处理中,为了提升处理速度,经常会启动多个线程同时处理,处理完毕后再合并请求结果返回。
在一些特殊情况下,业务处理过程中,会启动异步任务去计算,主线程不等待异步任务结束便返回结果。而该异步任务的结果会存在分布式缓存 Redis 中,供下一阶段业务处理使用。问题产生在原因是,我们需要录制主线程和异步任务的数据,但是难以判断请求的处理何时真正结束。一般都是在接口返回数据给调用方时,就认为请求处理结束了,此 case 的数据录制完成。而这里需要等待异步任务结束,才算真正录制完成。
解决办法是:新增任务标记 API,用于标记异步任务的启动和结束,在业务代码中进行标记。
代码规范问题在业务系统中引入模块级自动化测试时,发现一些通用的问题:
模块级自动化测试的思路是:在线上环境录制 case,通过录制请求处理过程中的所有对外交互,实现对外部环境依赖的解耦。在线下测试环境回放测试 case,并且 DIFF 对于对外输出。
在业务系统接入过程中,遇到的问题,一些是代码规范问题,一些是特殊业务逻辑造成的问题。其中,第二类问题严重影响接入效率。


| 欢迎光临 黑马程序员技术交流社区 (http://bbs.itheima.com/) | 黑马程序员IT技术论坛 X3.2 |