|
安装环境如下: Linux: Centos6.5 Jdk: jdk-7u79-linux-x64 Hadoop: hadoop-2.5.2.tar 一.为方便记忆,修改一下主机名: 修改一下两个文件 vim /etc/sysconfig/network ![]()
vim /etc/hosts(此步骤可以不必设置,没有效果) ![]()
重启一下,再查看是否成功 重启:reboot 查看机器名:hostname 现在开始安装hadoop 2.5.2 创建hadoop用户 useradd hadoop 为hadoop设置密码 passwd hadoop (输入两次) SSH 无密码登陆,切换到hadoop用户 su hadoop ssh-keygen -t rsa -P ''(实际使用的是ssh-keygen -t rsa)另外最后为2个单引号,不是双引号,也可改为2个双引号,代表 p password 为空。 此语句输入后,一直按enter默认选择即可。 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 2)设置SSH配置 用root用户登录服务器修改SSH配置文件"/etc/ssh/sshd_config"的下列内容。 vim /etc/ssh/sshd_config RSAAuthentication yes # 启用 RSA 认证 PubkeyAuthentication yes # 启用公钥私钥配对认证方式 AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同) ![]()
修改权限: chmod 700 /home/hadoop/.ssh/authorized_keys 设置完之后记得重启SSH服务,才能使刚才设置有效。 service sshd restart 退出root登录,使用hadoop普通用户验证是否成功, ssh localhost 不再需要输入密码便成功了
![]()
二.下载hadoop安装包 可以去Apache官方网站下载,或者国内镜下载。 阿里云镜像下载: http://mirrors.aliyun.com/ Apache官方下载:http://hadoop.apache.org/releases.html trieuvan下载:http://www.trieuvan.com/apache/ 这里使用之前配置好的ftp服务,上传本地已下载好的hadoop-2.5.2安装包。 ![]()
1. 拷贝安装包到/usr/local 目录,并且解压。 拷贝: cp /home/ftpuser/hadoop-2.5.2.tar.gz /usr/local/ 进入目录: cd /usr/local/ 解压: tar -zxvf hadoop-2.5.2.tar.gz 删除安装包: rm -f hadoop-2.5.2.tar.gz 更改用户,用户组 chown -R hadoop:hadoop hadoop-2.5.2/ (注意要到相应的hadoop安装文件夹的目录中操作执行,当前用户为root) ![]()
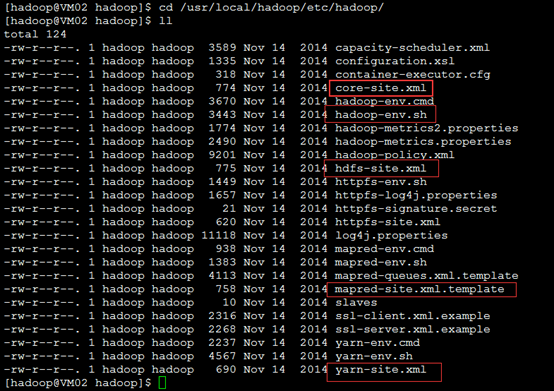
修改hadoop2.5.2安装目录名称 mv hadoop-2.5.2 hadoop 2.修改配置 在/home/hadoop/.bashrc文件末尾添加下列内容: vim /home/hadoop/.bashrc #HADOOP START export JAVA_HOME=/usr/local/java/jdk1.7.0_79 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP END 保存退出后,激活新加的环境变量 source /home/hadoop/.bashrc 3.测试验证 创建输入的数据,暂时采用/etc/protocols文件作为测试 cd /usr/local/hadoop mkdir input cp /etc/protocols ./input 执行自带的单词统计程序,验证单机安装是否正确 bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.5.2-sources.jar org.apache.hadoop.examples.WordCount input output 查看生成的单词统计数据 cat output/* 自此单机安装结束。 在单机模式的基础上进一步配置出伪分布模式。 要修改以下文件,在/usr/local/hadoop/etc/hadoop/目录下,如图 ![]()
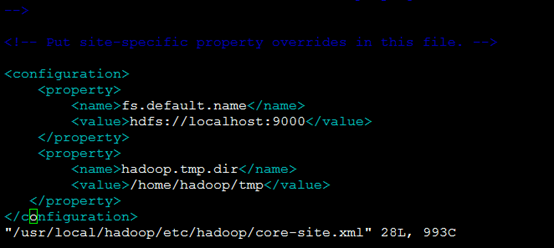
1.配置文件修改 1).修改core-site.xml vim /usr/local/hadoop/etc/hadoop/core-site.xml <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp</value> </property> ![]()
2).修改hdfs-site.xml vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml <property> <name>dfs.replication</name> <value>1</value> </property> ![]()
3).修改mapred-site.xml cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml vim /usr/local/hadoop/etc/hadoop/mapred-site.xml <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> ![]()
4).修改yarn-site.xml vim /usr/local/hadoop/etc/hadoop/yarn-site.xml <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> ![]()
5).修改hadoop-env.sh vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh 找到 #export JAVA_HOME=${JAVA_HOME} 修改为: export JAVA_HOME=/usr/local/java/jdk1.7.0_79 ![]()
伪分布式模式就配置好了。 2.格式化HDFS文件系统 切换到hadoop用户 hadoop namenode -format 会输出如下信息,则表格式化HDFS成功: ![]()
四、Hadoop集群启动 1.启动hdfs守护进程,分别启动NameNode和DataNode hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode 以上两个命令等于:start-dfs.sh 2.启动yarn,使用如下命令启ResourceManager和NodeManager: yarn-daemon.sh start resourcemanager yarn-daemon.sh start nodemanager 或者等价于下面: start-yarn.sh 全部启动完成后,用jps查看进程 ![]()
3.检查是否运行成功 打开浏览器 输入:http://localhost:8088进入ResourceManager管理页面 输入:http://localhost:50070进入HDFS页面 如果打不开,可能是8088和50070端口没打开。 vi /etc/sysconfig/iptables 加入以下内容 -A INPUT -m state --state NEW -m tcp -p tcp --dport 21 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 8088 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 50070 -j ACCEPT ![]()
然后重启路由生效 service iptables restart 六、伪分布测试验证 创建目录: hadoop dfs -mkdir /user hadoop dfs -mkdir /user/hadoop hadoop dfs -mkdir /user/hadoop/input 拷贝测试数据: hadoop dfs -put /etc/protocols /user/hadoop/input 查看已经准备好的测试数据 hadoop dfs –ls /user/hadoop/input
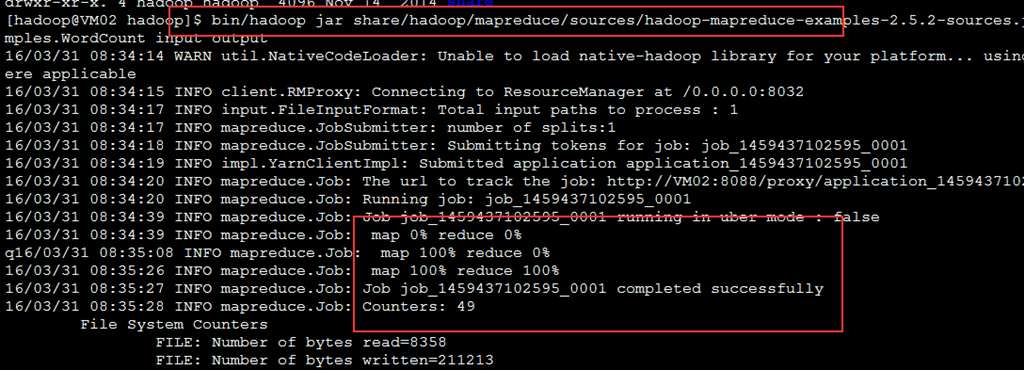
执行应用 bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.5.2-sources.jar org.apache.hadoop.examples.WordCount input output ![]()
查看生成结果 hadoop dfs -cat /user/hadoop/output/* ![]()
七、关闭服务,注意关闭顺序 输入命令 hadoop-daemon.sh stop namenode hadoop-daemon.sh stop datanode yarn-daemon.sh stop resourcemanager yarn-daemon.sh stop nodemanager 或者 stop-dfs.sh stop-yarn.sh 【转载】https://blog.csdn.net/qq_36178899/article/details/81735232
|